※ 카프카를 구성하는 주요 요소
- 주키퍼(Zookeeper) : 아파치 프로젝트 애플리케이션 이름이다. 카프카의 메타데이터(metadata) 관리 및 브로커의 정상상태 점검(health check)를 담당한다.
- 카프카(Kafka) 또는 카프카 클러스터(Kafka cluster) : 아파치 프로젝트 애플리케이션 이름이다. 여러 대의 브로커를 구성한 클러스터를 의미한다.
- 브로커(broker) : 카프카 애플리케이션이 설치된 서버 또는 노드를 말한다.
- 프로듀서(producer) : 카프카로 메시지를 보내는 역할을 하는 노드를 말하낟.
- 컨슈머(consumer) : 카프카에서 메시지를 꺼내가는 역할을 하는 클라이언트를 총칭하낟.
- 토픽(topic) : 카프카는 메시지 피드들을 토픽으로 구분하고, 각 토픽의 이름은 카프카 내에서 고유하다.
- 파티션(partition) : 병렬 처리 및 고성능을 얻기 위해 하나의 토픽을 여러 개로 나눈 것을 의미한다.
- 세그먼트(segment) : 프로듀서가 전송한 실제 메시지가 브로커의 로컬 디스크에 저장되는 파일을 말한다.
- 메시지(message) or 레코드(record) : 프로듀서가 브로커로 전송하거나 컨슈머가 읽어가는 데이터 조각을 말한다.
1. 리플리케이션 [Replication]
: 카프카에서 리플리케이션(replication)이란 각 메시지들을 여러 개로 복제해서 카프카 클러스터 내 브로커들에 분산시키는 동작을 의미한다. 이러한 리플리케이션 동작 덕분에 하나의 브로커가 종료되어도 안정성을 유지할 수 있다.
- replication-factor 옵션 : 카프카 내 몇 개의 리플리케이션을 유지할지 설정
- 테스트나 개발 환경 : 리플리케이션 팩터 수를 1로 설정
- 운영 환경(로그성 메시지로서 약간의 유실 허용) : 리플리케이션 팩터 수를 2로 설정
- 운영 환경(유실 허용하지 않음) : 리플리케이션 팩터 수를 3으로 설정
2. 파티션 [Partition]
: 하나의 토픽이 한 번에 처리할 수 있는 한계를 높이기 위해 토픽 하나를 여러 개로 나눠 병렬 처리가 가능하게 만든 것을 파티션이라고 한다.
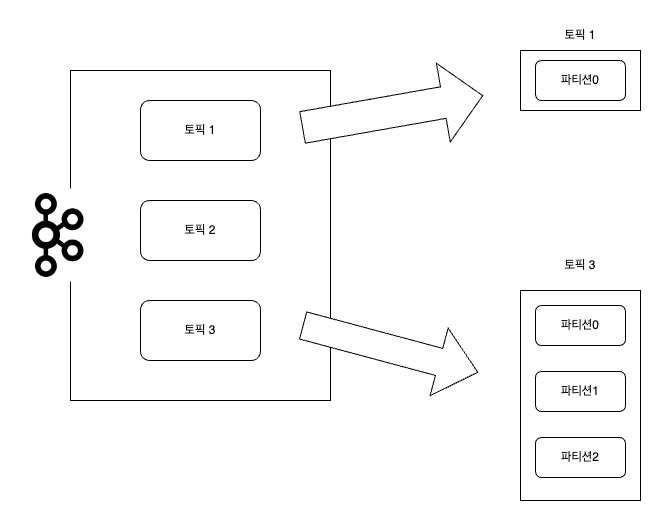
- [토픽1]은 {파티션0} 이라는 하나의 파티션으로 구성
- [토픽3]은 {파티션0, 파티션1, 파티션2}로 3개의 파티션으로 구성
- 파티션 수도 토픽을 생성할 때 옵션으로 설정하게 되는데, 파티션 수를 정하는 기준은 다소 모호한 경우가 많다. 각 메시지 크기나 초당 메시지 건수 등에 따라 달라지므로 상황에 맞게 유연하게 설정해야 한다.
- 특히 파티션 수는 초기 생성 후 언제든지 늘릴 수 있지만, 반대로 한 번 늘린 파티션 수는 절댈 줄일 수 없다.
- 초기에 파티션 수를 작게 설정 한 후, 메시지 처리량이나 컨슈머의 LAG 등을 모니터링하며 늘려가야 한다.
- LAG = (프로듀서가 보낸 메시지 수) - (컨슈머가 가져간 메시지 수)
3. 세그먼트 [Segment]
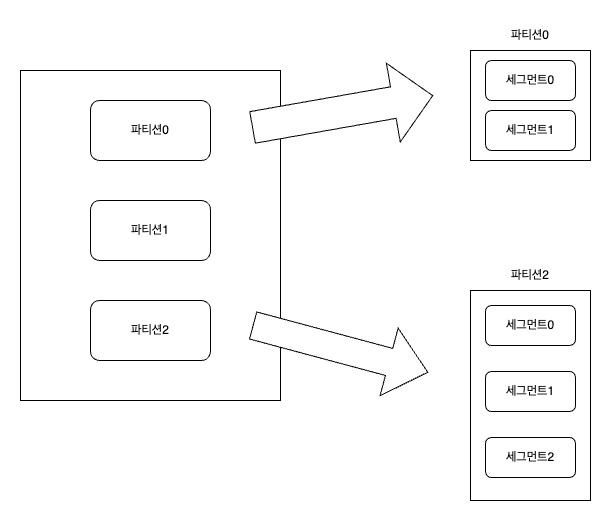
: 프로듀서를 이용해 보낸 메시지는 토픽의 파티션에 저장되어 있다. 이처럼 프로듀서에 의해 브로커로 전송된 메시지는 토픽의 파티션에 저장되며, 각 메시지를 세그먼트(segment)라는 로그 파일의 형태로 브로커의 로컬 디스크에 저장된다.
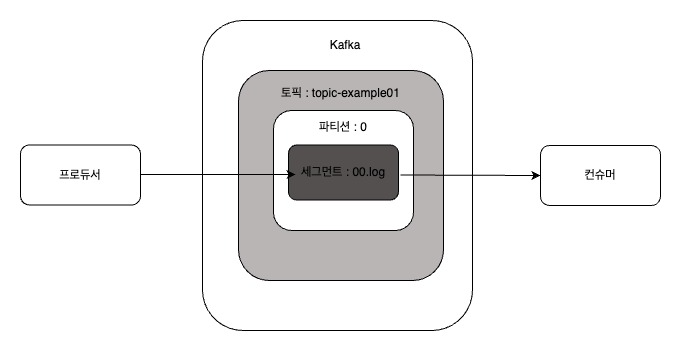
- 프로듀서는 카파카의 topic_example01 토픽으로 메시지를 전송한다
- topic_example01 토픽은 파티션이 하나뿐이므로, 프로듀서로부터 받은 메시지를 파티션0의 세그먼트 로그 파일에 저장한다.
- 브로커의 세그먼트 로그 파일에 저장된 메시지는 컨슈머가 읽어갈 수 있다.
4. 카프카의 핵심 개념
4-1. 분산 시스템
※ 분산 시스템은 네트워크 상에서 연결된 컴퓨터들의 그룹을 말하며, 단일 시스템이 갖지 못한 높은 성능을 목표로 한다. 이러한 분산 시스템은 성능이 높다는 장점 이외에도 하나의 서버 또는 노드 등에 장애가 발생할 때 다른 서버 또는 노드가 대신 처리하므로 장애 대응이 탁월하며, 부하가 높은 경우에는 시스템 확장이 용이하다는 장점도 있다.
- 카프카도 분산 시스템이므로 최초 구성한 클러스터의 리소스가 한계치에 도달해 더욱 높은 메시지 처리량이 필요한 경우, 브로커를 추가하는 방식으로 확장이 가능하다.
4-2. 페이지 캐시
- 카프카는 OS의 페이지 캐시를 활용하는 방식으로 설계되어 있다.
- 페이지 캐시는 직접 디스크에 읽고 쓰는 대신 물리 메모리 중 애플리케이션이 사용하지 않는 일부 잔여 메모리를 활용한다.
- 페이지 캐시를 이용하면 디스크 I/O에 대한 접근이 줄어들므로 성능을 높일 수 있다.

4-3. 배치 전송 처리와 압축 전송
- 카프카에서는 배치 전송을 지원하므로 배치 전송을 권장한다.
- 카프카는 메시지 전송 시 좀 더 성능이 높은 압축 전송을 사용하는 것을 권장한다.
- 지원하는 압축 타입은 gzip, snappy, lz4, zstd 등이다.
4-4. 토픽, 파티션, 오프셋
- 카프카는 토픽이라는 곳에 데이터를 저장하며, 토픽은 병렬 처리를 위해 여러 개의 파티션이라는 단위로 다시 나눈다.
- 카프카에서는 이와 같은 파티셔닝을 통해 단 하나의 토픽이라도 높은 처리량을 수행할 수 있다.
- 이 파티션의 메시지가 저장되는 위치를 오프셋(offset)이라고 부르며, 오프셋은 순차적으로 증가하는 숫자(64비트 정수)형태로 되어 있다.

- 3개의 파티션으로 나뉘며 각 파티션마다 증가하는 숫자들이 오프셋(offset)이다.
4-5. 고가용성 보장
- 카프카는 앞서 설명한 것처럼 분산 시스템이기 때문에 하나의 서버나 노드가 다운되어도 다른 서버 또는 노드가 대신 역할을 수행해 안정적인 서비스가 가능하다.
- 이러한 고가용성을 보장하기 위해 카프카에서는 리플리케이션 기능을 제공한다.
- 리플리케이션 기능은 토픽 자체를 복제하는 것이 아니라 토픽의 파티션을 복제하는 것이다.
- 토픽을 생성할 때 옵션으로 리플리케이션 팩터 수를 지정할 수 있으며, 이 숫자에 따라 리플리케이션들이 존재하게 된다.
- 원본과 리플리케이션을 구분하기 위해 카프카에서는 "리더(leader)"와 "팔로워(follower)"라고 부른다.
| 리플리케이션 팩터 수 | 리더 수 | 팔로워 수 |
| 2 | 1 | 1 |
| 3 | 1 | 2 |
| 4 | 1 | 3 |
- 일반적으로 카프카에서는 리플리케이션 팩터 수를 3으로 구성하도록 권장한다.
- 리더는 프로듀서, 컨슈머로부터 오는 모든 읽기와 쓰기 요청을 처리하며, 팔로워는 오직 리더로부터 리플리케이션 하게 된다.
4-6. 주키퍼의 의존성
카프카를 언급하면서 빼놓을 수 없는 부분이 바로 주키퍼이다.
- 주키퍼는 여러 대의 서버를 앙상블(클러스터)로 구성하고, 살아 있는 노드 수가 과반수 이상 유지된다면 지속적인 서비스가 가능한 구조이다. 따라서 노드 수는 반드시 홀수로 구성한다.
- 현재 Kafka는 주키퍼 의존성이 제거된 상태로 설계가 가능하다.
- 카프카의 중요한 메타데이터를 저장하고 각 브로커를 관리하는 중요한 역할을 하는 것이 주키퍼라는 사실만 인지하면 된다.
5. 프로듀서의 기본 동작

- ProducerRecord라고 표시된 부분은 카프카로 전송하기 위한 실제 데이터이며, 레코드는 토픽, 파티션, 키, 밸류로 구성된다
- 프로듀서가 카프카로 레코드를 전송할 때, 카프카의 특정 토픽으로 메시지를 전송한다. 따라서 레코드에서 토픽과 밸류(메시지 내용)은 필숫값이며, 특정 파티션을 지정하기 위한 레코드의 파티션과 특정 파티션에 레코드를 정렬하기 위한 레코드의 키는 선택값(옵션)이다.
- 다음으로 각 레코드들은 프로듀서의 send() 메소드를 통해 시리얼라이저(serializer), 파티셔너(partitioner)를 거치게 된다.
- 만약 프로듀서 레코드의 선택사항인 파티션을 지정했다면, 파티셔너는 아무 동작도 하지 않고 지정된 파티션으로 레코드를 전달한다.
- 기본적으로는 라운드-로빈 방식으로 동작한다.
- 이렇게 프로듀서 내부에서는 send() 메소드 동작 이후 레코드들을 파티션 별로 잠시 모아두게 된다.
- 레코드들을 모아두는 이유는 프로듀서가 카프카로 전송하기 전, 배치 전송을 하기 위함이다.
[프로듀서의 주요 옵션]
| 프로듀서 옵션 | 설명 |
| client.dns.lookup | 하나의 호스트에 여러 IP를 매핑해 사용하는 일부 환경에서 클라이언트가 하나의 IP와 연결하지 못할 경우에 다른 IP로 시도하는 설정이다. - use_all_dns_ips가 기본값으로, DNS에 할당된 호스트의 모든 IP로 접근을 시도한다. - resolve_canonical_bootstrap_servers_only 옵션은 커버로스(Kerberos) 환경에서 FQDN을 얻기 위한 용도로 사용 |
| * acks | 프로듀서가 카프카 토픽의 리더 측에 메시지를 전송한 후 요청을 완료하기를 결정하는 옵션 - 0 (빠른 전송) : 메시지 손실 가능성 존재 - 1 (메시지 수신 확인하지만 모든 팔로워 확인x) : 대부분 1로 설정하여 사용 - all (팔로워가 메시지를 받았는지 여부를 확인) : 메시지 손실 x, but 다소 느림 |
| * enable.idempotence | 설정을 true로 하는 경우 중복 없는 전송이 가능하며 이와 동시에 max.in.flight.requests.per.connection은 5 이하, retries는 0이상, acks는 all로 설정해야 한다. |
| max.in.flight.requests.per.connection | 하나의 커넥션에서 프로듀서가 최대한 ACK 없이 전송할 수 있는 요청 수이다. 메시지의 순서가 중요하다면 1로 권장, 하지만 성능은 다소 떨어짐 |
| retries | 일시적인 오류로 인해 전송에 실패한 데이터를 다시 보내는 횟수 |
| batch.size | 적절한 배치 크기 설정 |
| * transactional.id | '정확히 한 번 전송'을 위해 사용하는 옵션이며, 동일한 TransactionalId에 한해 정확히 한 번을 보장한다. - 옵션을 사용하기 전 enable.idempotence를 true로 설정해야한다. |
6. 컨슈머의 기본 동작
프로듀서가 카프카의 토픽으로 메시지를 전송하면 해당 메시지들은 브로커들의 로컬 디스크에 저장된다. 그리고 사용자는 컨슈머를 이용해 토픽에 저장된 메시지들을 가져올 수 있다.
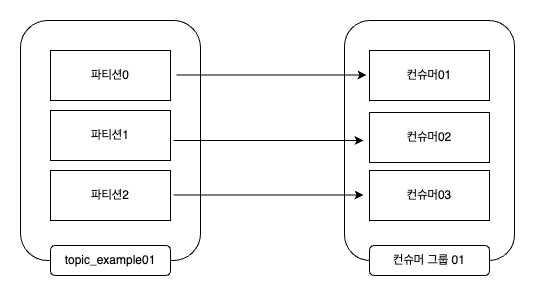
- 컨슈머 그룹은 하나 이상의 컨슈머들이 모여 있는 그룹을 의미하고, 컨슈머는 반드시 컨뮤서 그룹에 속하게 된다
- 컨슈머 그룹은 각 파티션의 리더에게 카프카 토픽에 저장된 메시지를 가져오기 위한 요청을 보낸다.
- 이때 파티션 수와 컨슈머 수는 일대일로 매핑되는 것이 이상적이다. 무조건 일대일로 되어야 하는 것은 아니지만 파티션 수보다 컨슈머 수가 많게 구현되는 것은 바람직하지 않다.
'CS > Apache Kafka' 카테고리의 다른 글
| [Kafka - 03] 프로듀서의 내부 동작 원리와 구현, 중복 없는 전송 (0) | 2023.08.31 |
|---|---|
| [Kafka - 02] 카프카의 내부 동작 원리와 구현 (1) | 2023.08.25 |
| [Kafka - 00] 카프카 개요 및 특징, 구성 (0) | 2023.08.21 |
| Kafka 초기 설정 방법 - (Topic 생성 및 확인, Producer/Consumer 설정) (0) | 2023.05.08 |