728x90
반응형

H : 150, W : 150

- H : 150, W : 150, cn : 3, cw: 3, S : 1
- (150 - 3) / 1 + 1 = 148로 32개의 겹겹
- -> 148 x 148 x 32 : 1단계
- MaxPooling(2, 2) -> 74 x 74 형태로
계속해서 하다가 마지막 layers.Dense는 1, binary Data(고양이, 개) 이므로
MNIST는 10이었음

- 2번째 conv할 때는 (3, 3)적용 -> (74 - 3) / 1 + 1 = 72가 됨
- 64개의 Filter였으므로 (3x3x32+1)x64
- 이거 꼭 해봐야함
- dense layer(512) 계산하면 Parameter 값은 3211776

- train data set은 200개
- optimizer : 파라미터 찾는 것
- loss는 binary -> 데이터도 binary였으므로

2000개를 100번 나눠서
스텝당 100번, 전체 30번 -> 3000번
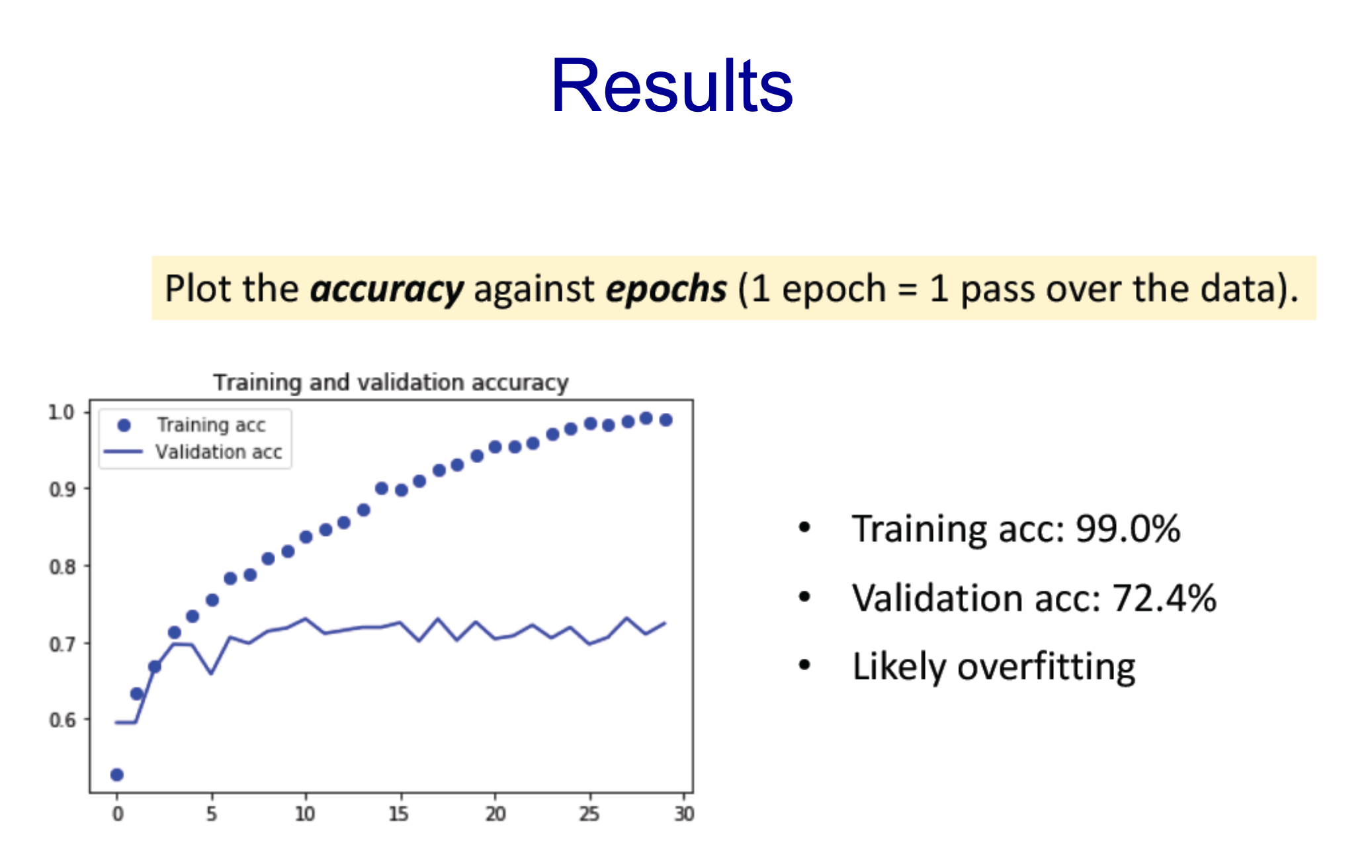
- 더 중요한 Validation acc가 72임
- 무슨 문제가 있을까 -> overfitting
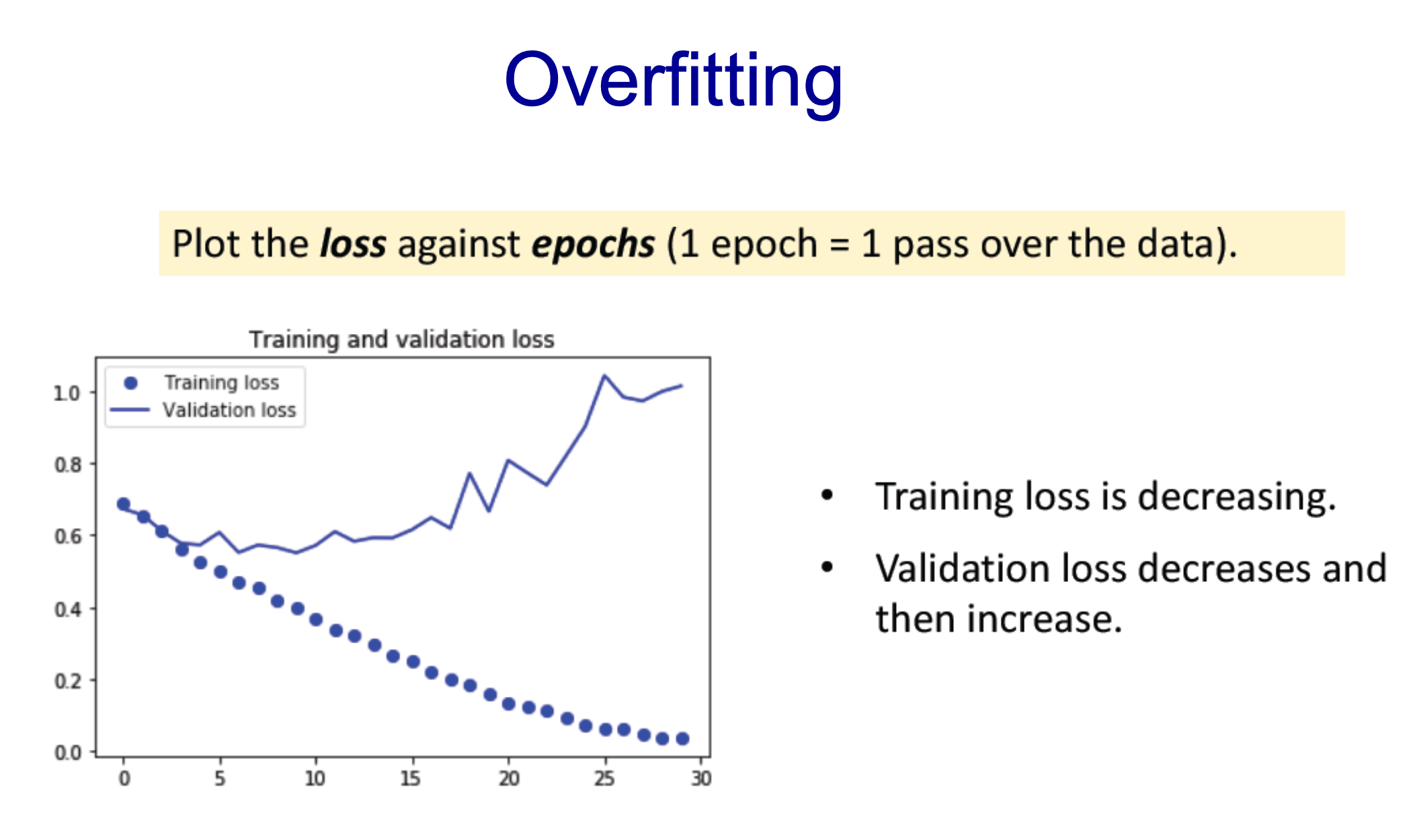
- loss를 봤을 때 validation의 경우 loss가 어느 순간부터 다시 상승
- 더 나은 학습 방법이 필요함
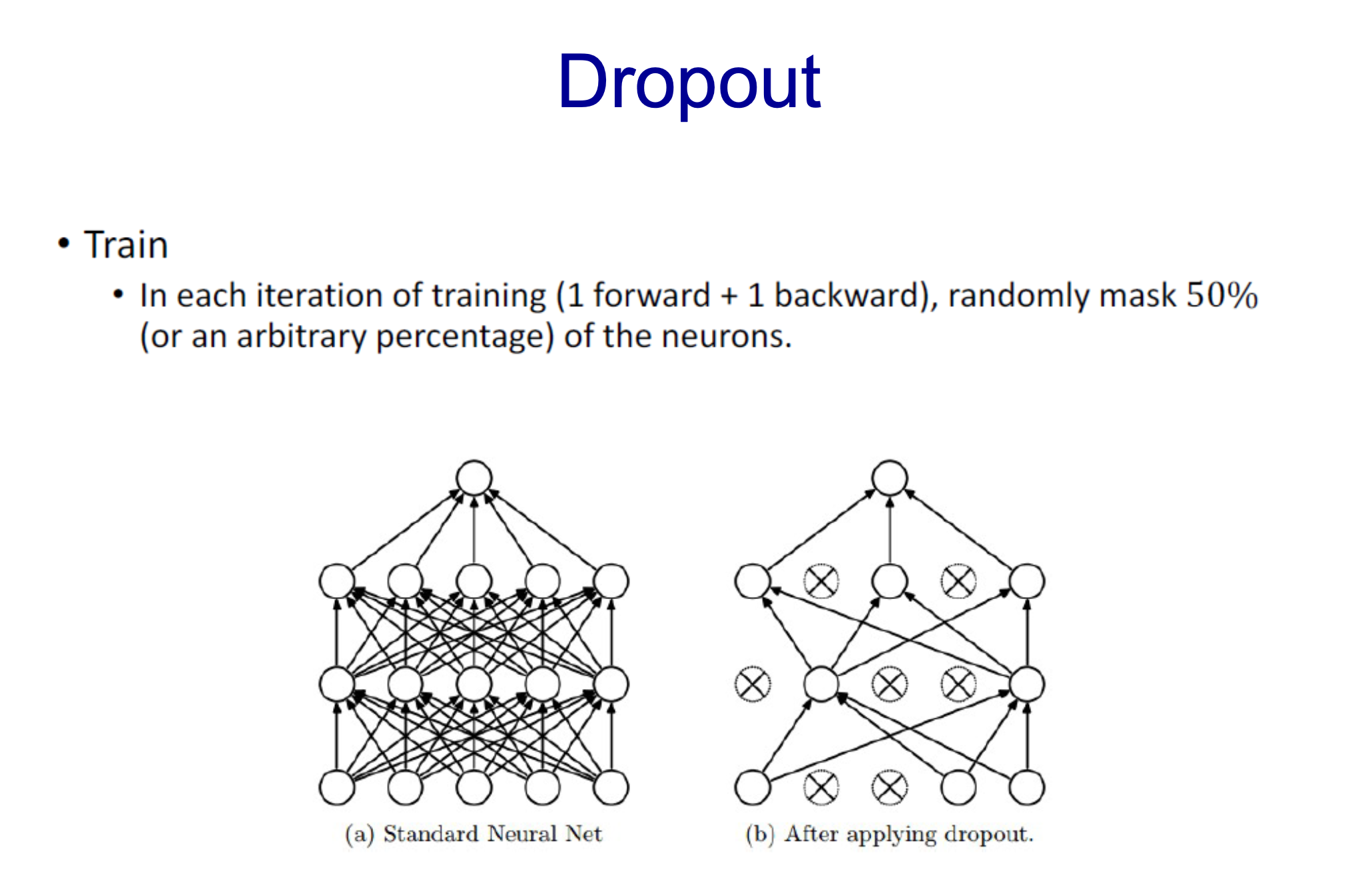
- 데이터 Train을 할 때 마지막에 도달한 후 일치하지 않을 때 50% 양을 back propagation(mask)함

- 학습할 때만 mask를 함
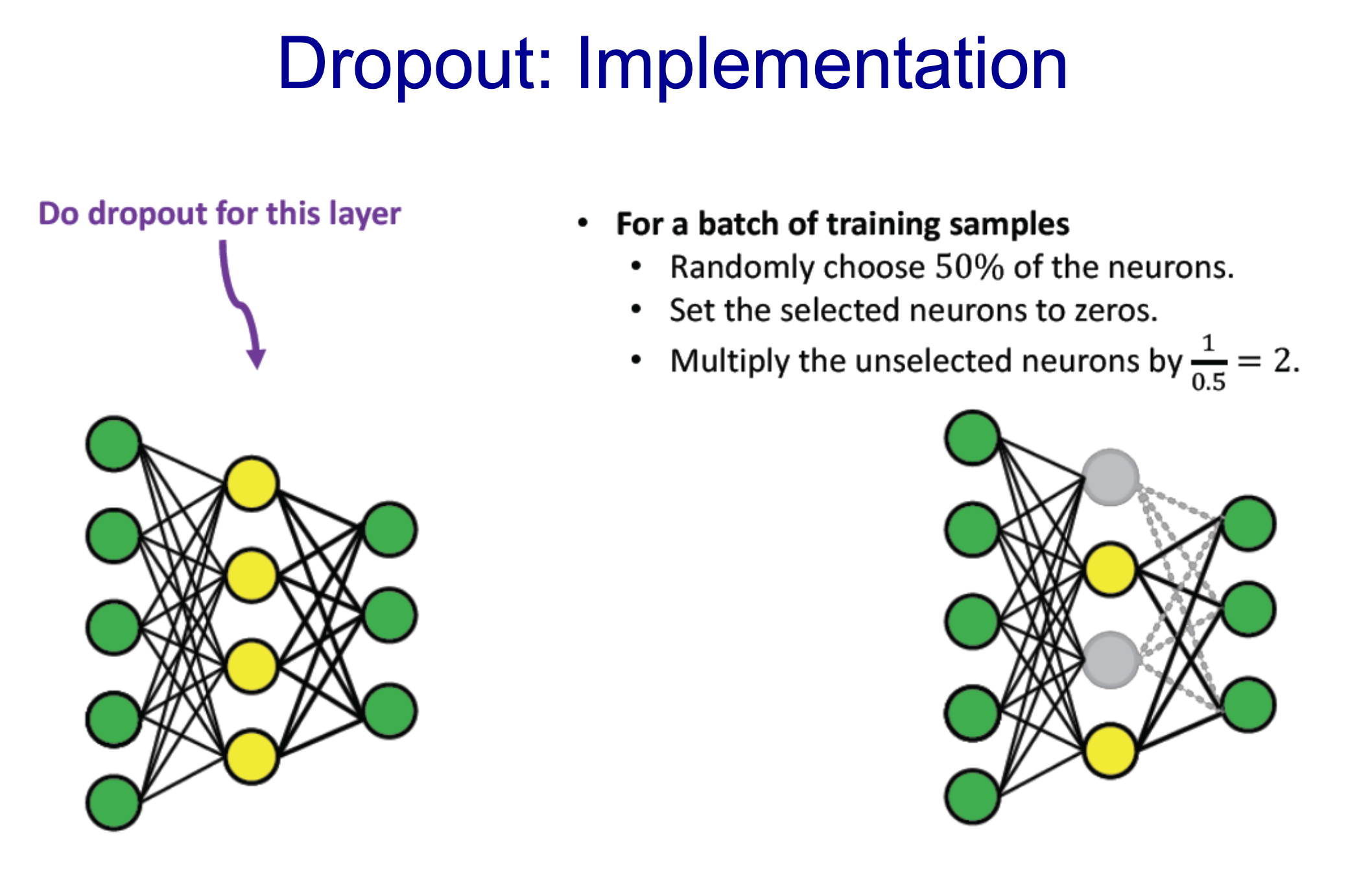
- Yellow Layer에서 Dropout 적용
- 1/2개를 0으로 두고 나머지는 (x2)함
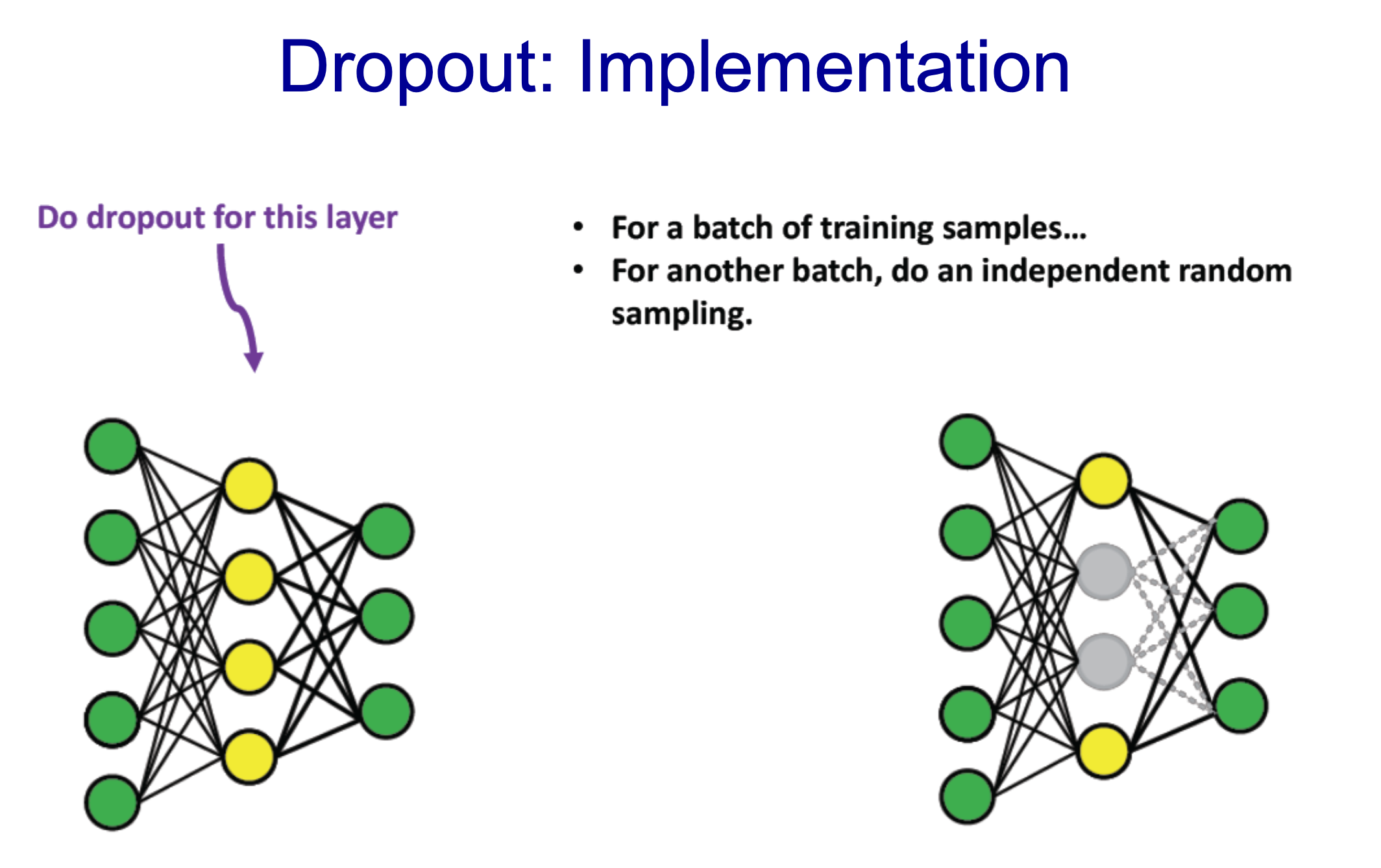
- Batch를 할 때마다 다른 노드를 랜덤하게 새로 결정하여 mask를 함
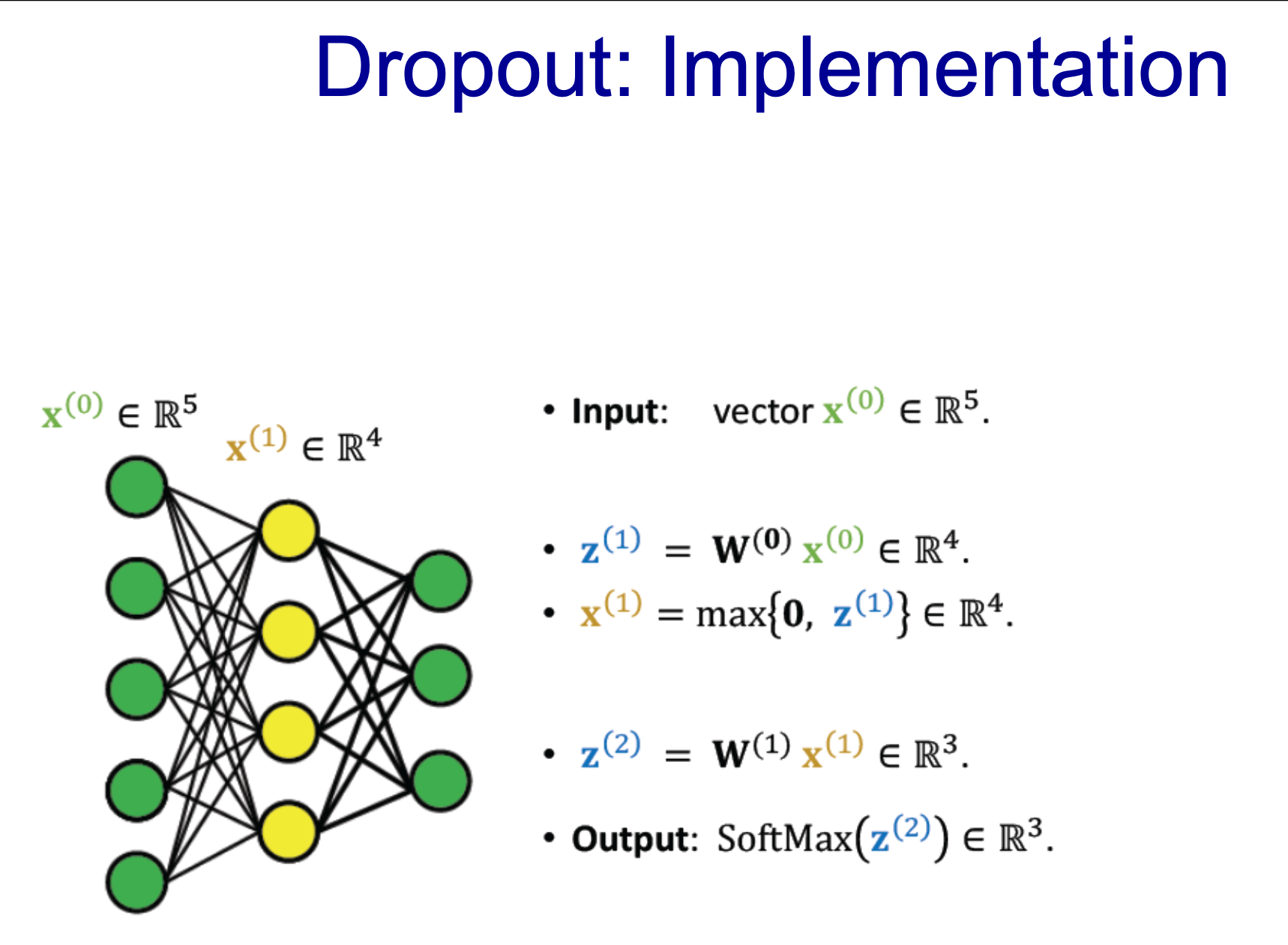
- w(0)의 사이즈는 [input 5개 : out 4개] -> 따라서 사이즈는 20개 + 거기에 Rele(R^4) 적용하면 x(1)
- w(1)의 사이즈는 12개, softmax를 적용, fully connected
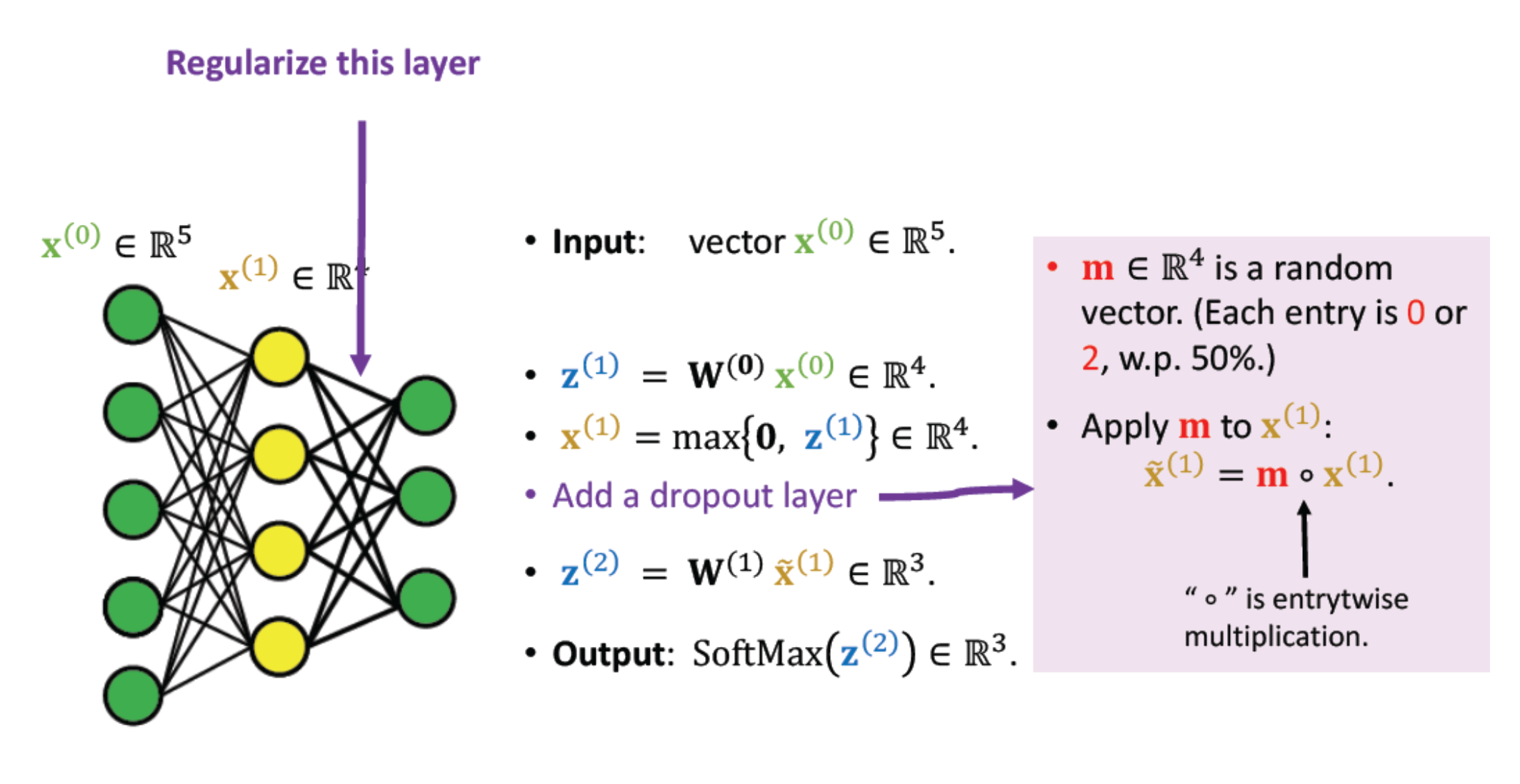
- 4개 사이즈의 m값을 통해 mask를 적용시킴

- keras에서 한 줄만 적용시키면 됨
- 위에서 보았듯이 첫 번째 dense layer에서 너무 많은 트레이닝 parameter가 존재하였기 때문에 적용

- 일부러 noise를 주어 strength를 높이는 느낌

- Network이 데이터의 일부만 사용하여 결정을 하게 함
- 정규화의 방법으로 볼 수 있음
- 오버피팅을 줄임
- L1 : [weight] 절대값 ; 너무 커지지 않게
- L2 : [weight]^2 절대값
- w값이 너무 커지면 트레이닝 데이터에 편향되어 이를 너무 커지지 않게 하기 위해

- 데이터를 2000개 사용하는데 Dropout 적용 전 1's Dense Layer에서 param이 300만이 넘었음
- 데이터의 수를 더 늘려줄 필요가 있음
- flip, rotation, crop, shift, random noise를 사용하여 데이터를 다른 방식으로 늘리는 것

- method임 : 한 줄만 추가하면 적용 가능

- 한 줄만 주가해주면 됨
- 결과가 확실히 좋아질 여력이 존재
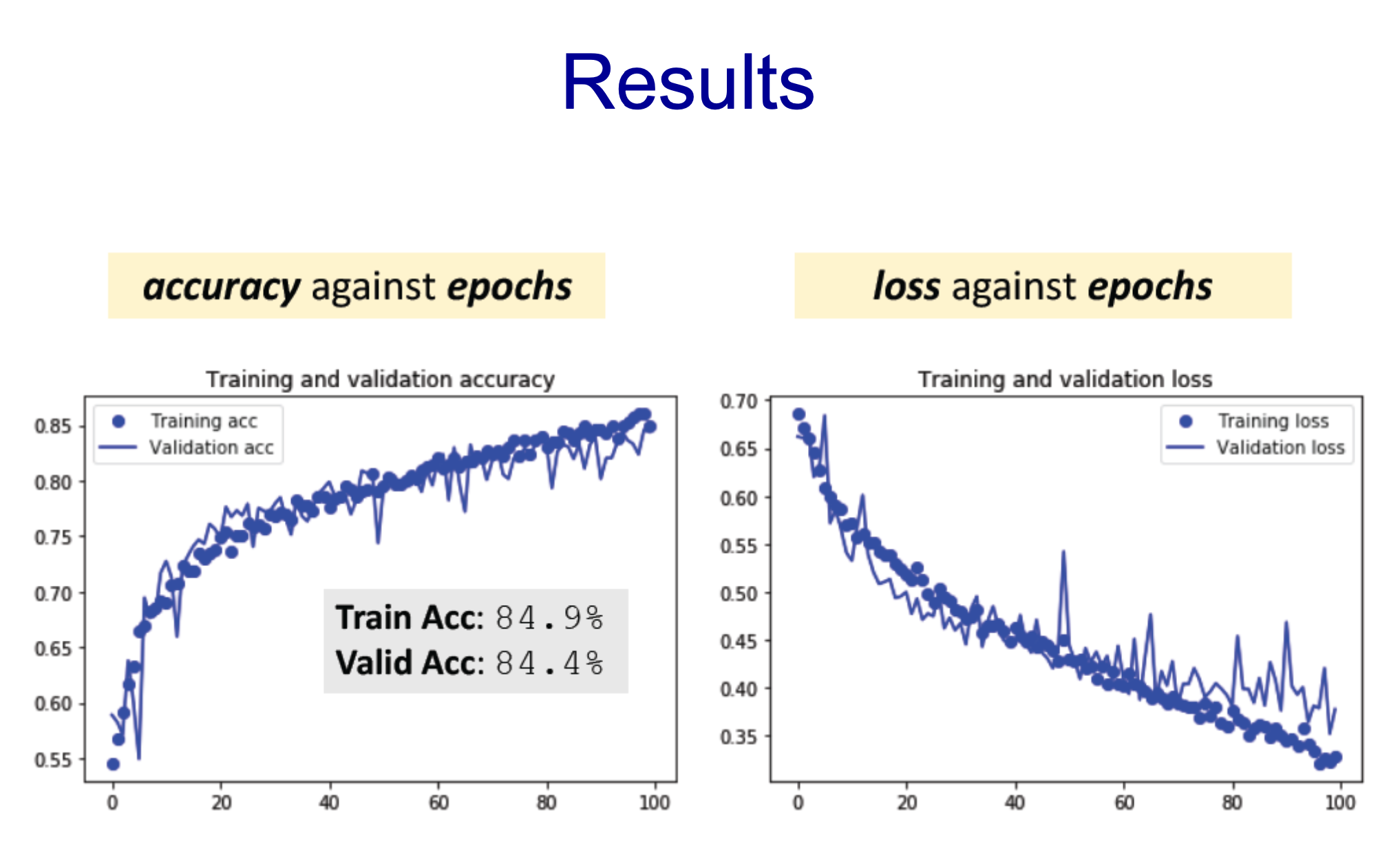

- 이미지 데이터는 항상 사용하는 것을 권장
- layer 사용하면 너무 많은 param이 나올 경우, dropout도 적용하는 것 권장

- 학습하기 전 Train 기법
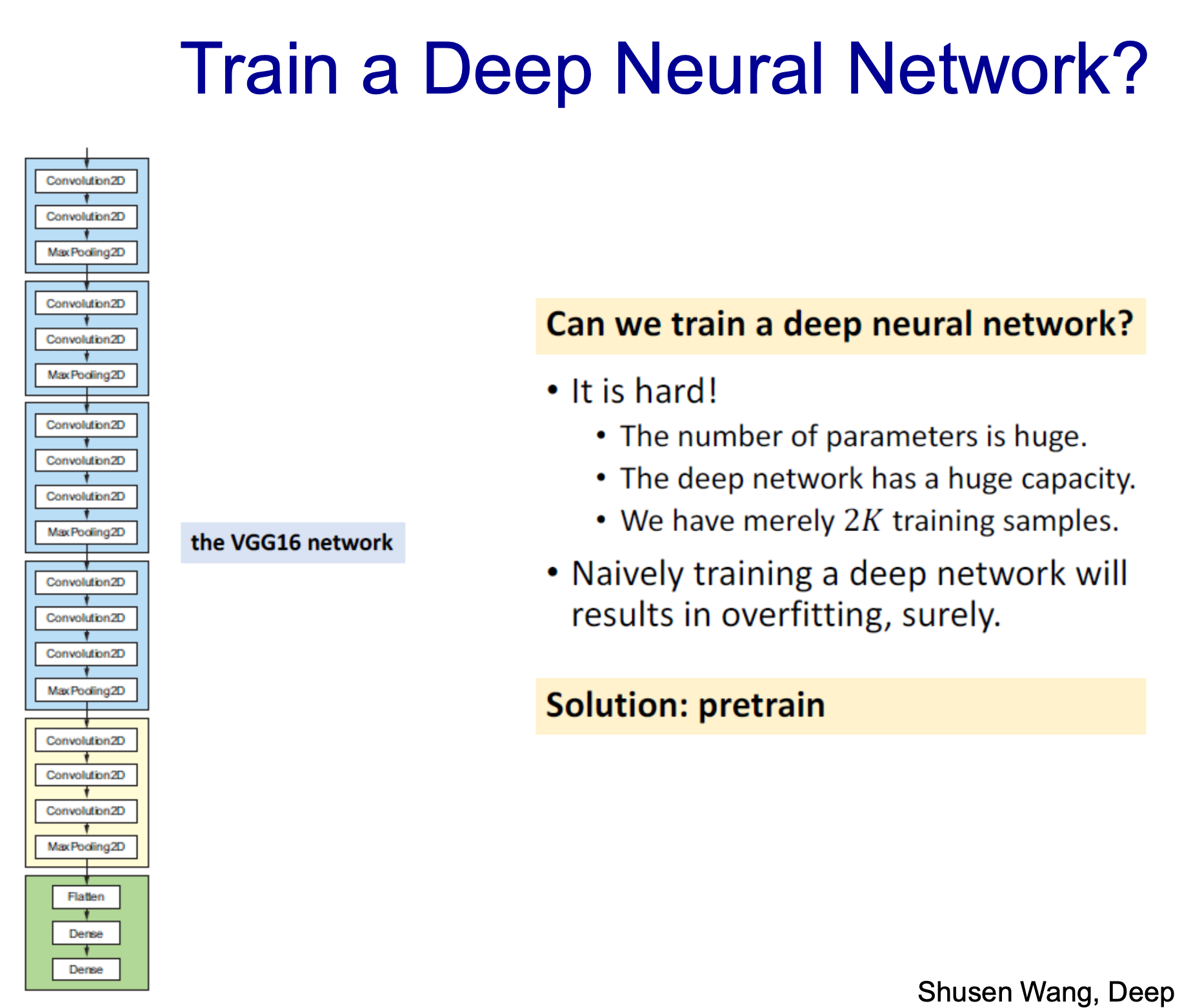
- 16개 layer로 2000개의 데이터를 적용하면 학습이 잘 될까?
- 300만개보다 훨 많아질 것 -> 학습 잘 안될거임
- pretrain 적용하면 해결 가능
- dropout, dat augmentation, pretain은 무조건 써야하는 기법들

- 이미 다른 데이터로 학습된 모델을 가져와 사용

- 우리는 판단하는 네트워크를 구축
- 따라서 Top layer를 제거하고 우리가 사용하고 하는 classfier적용시켜야함
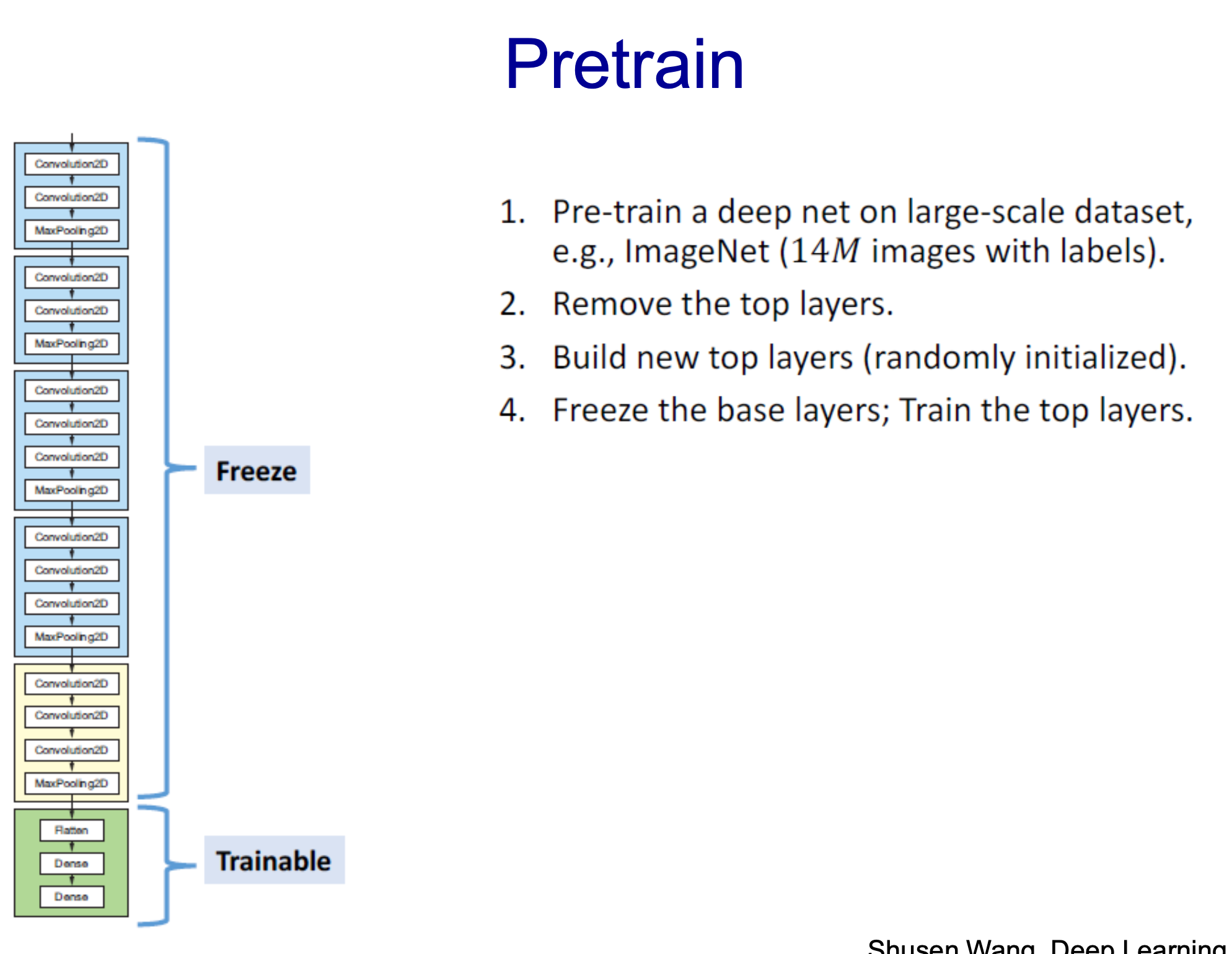
- 랜덤하게 initailzer하고 랜덤 학습
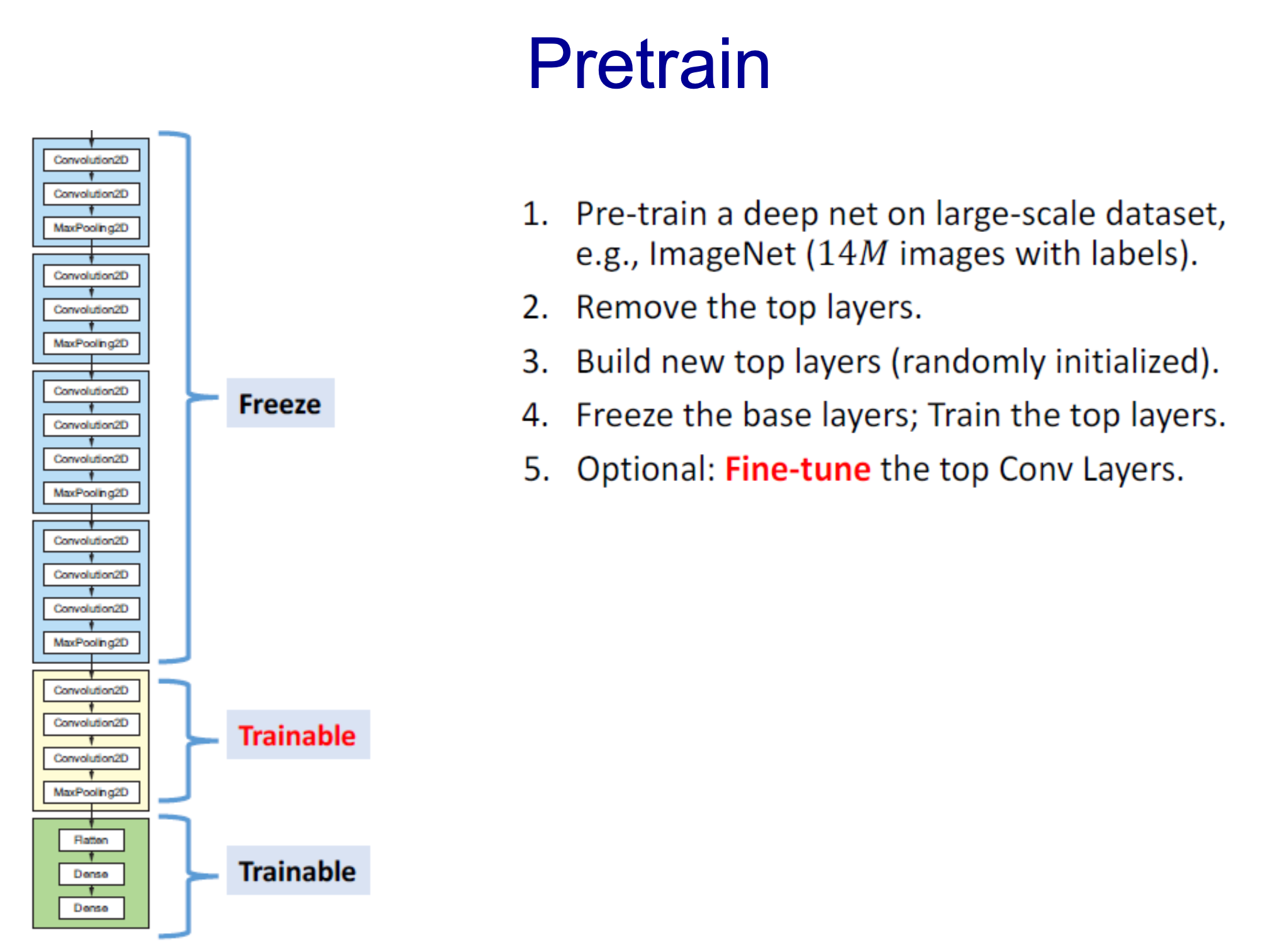
- optional하게 Trainable시킴
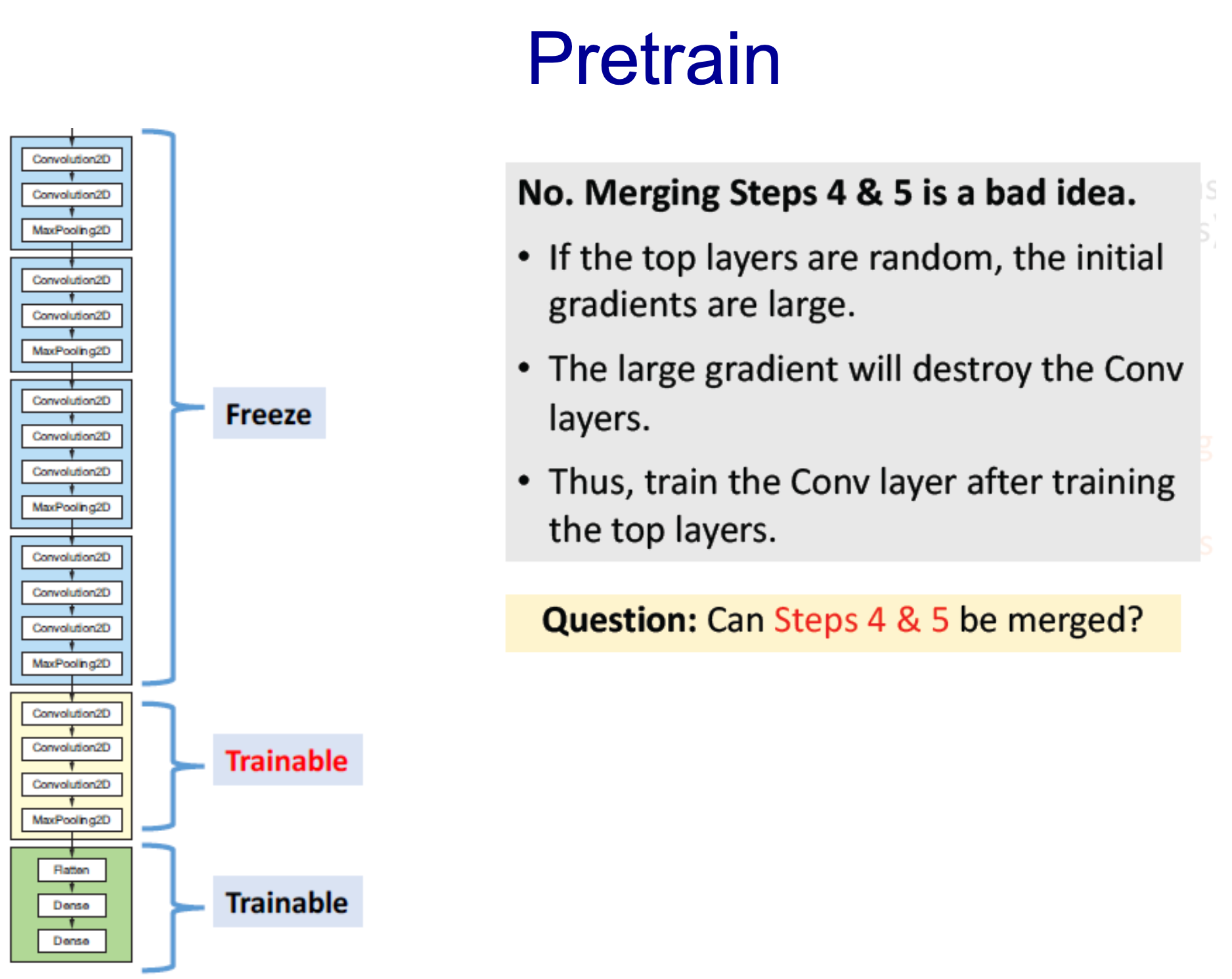
- 두 가지를 같이 학습하는 것은 좋은 생각이 아님
- 많은 변경사항이 생기는 것은 학습에 악영향
- 맨 처음에 맨 마지막 layer를 한 후 Convol layer를 Train하는 형태
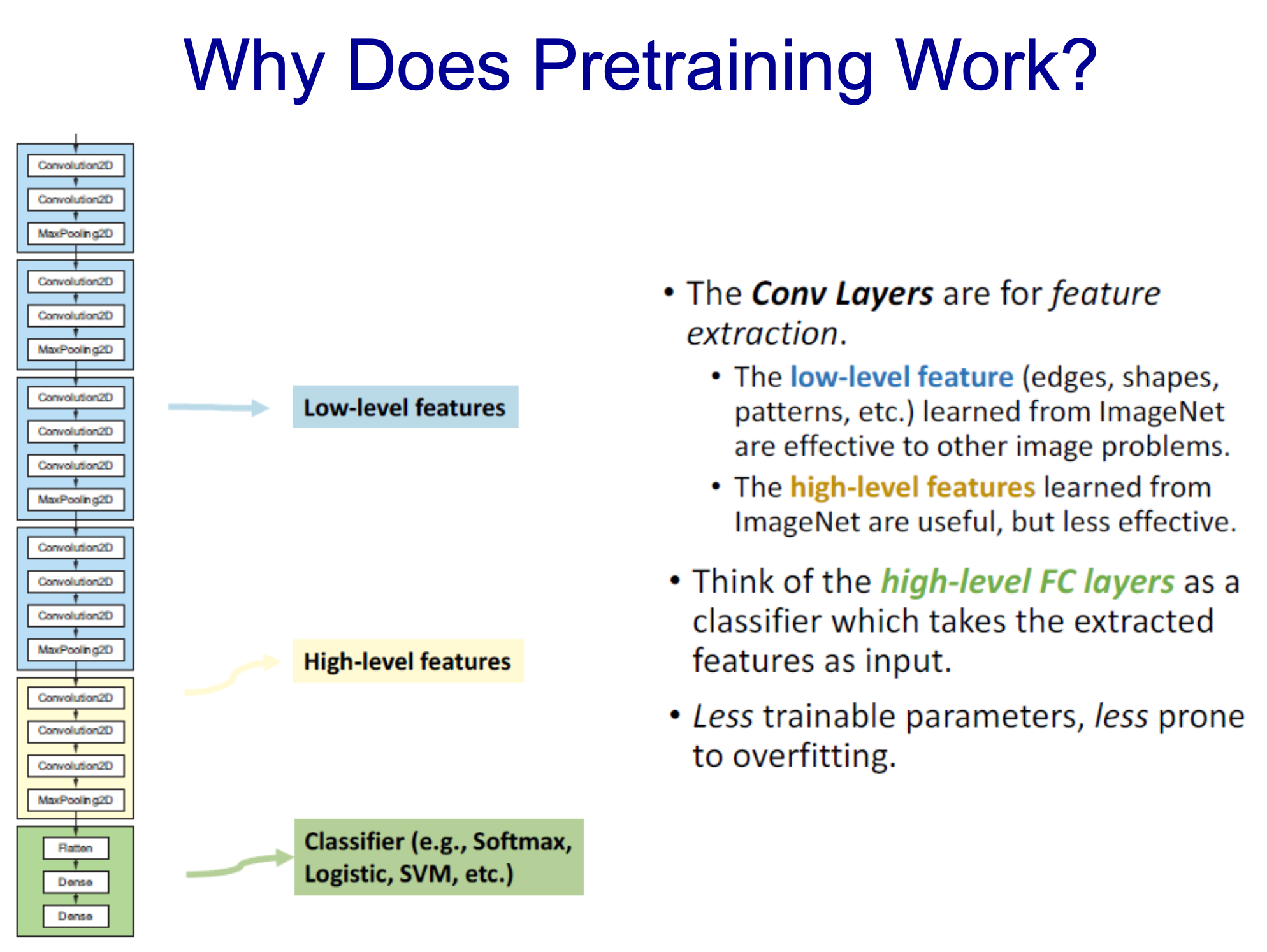
- low level layer는 이미 fix되어 학습할 파라미터가 적어짐
- overfitting 될 가능성도 줄어듦

- 위에서 정리한 학습 기법을 적용하면 더 나은 결과를 만들어낼 수 있다는 것을 볼 수 있음
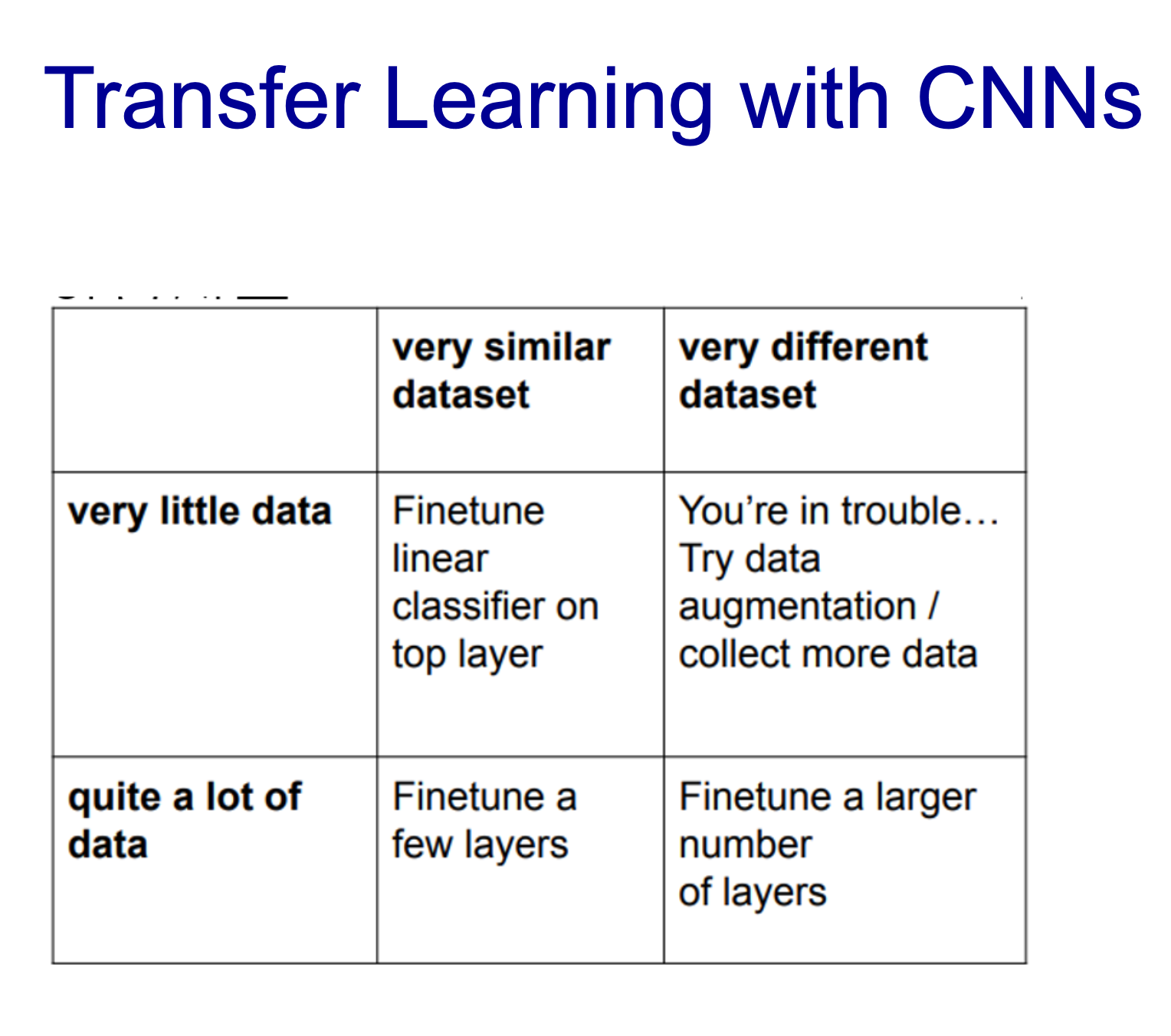
- 학습할 수 있는 범위가 줄수록 좋음
- 일단 데이터도 많을 수록 좋음

- bagging : 모델을 만들고 또 다른 모델을 만들어나가서 적용시키는 방법
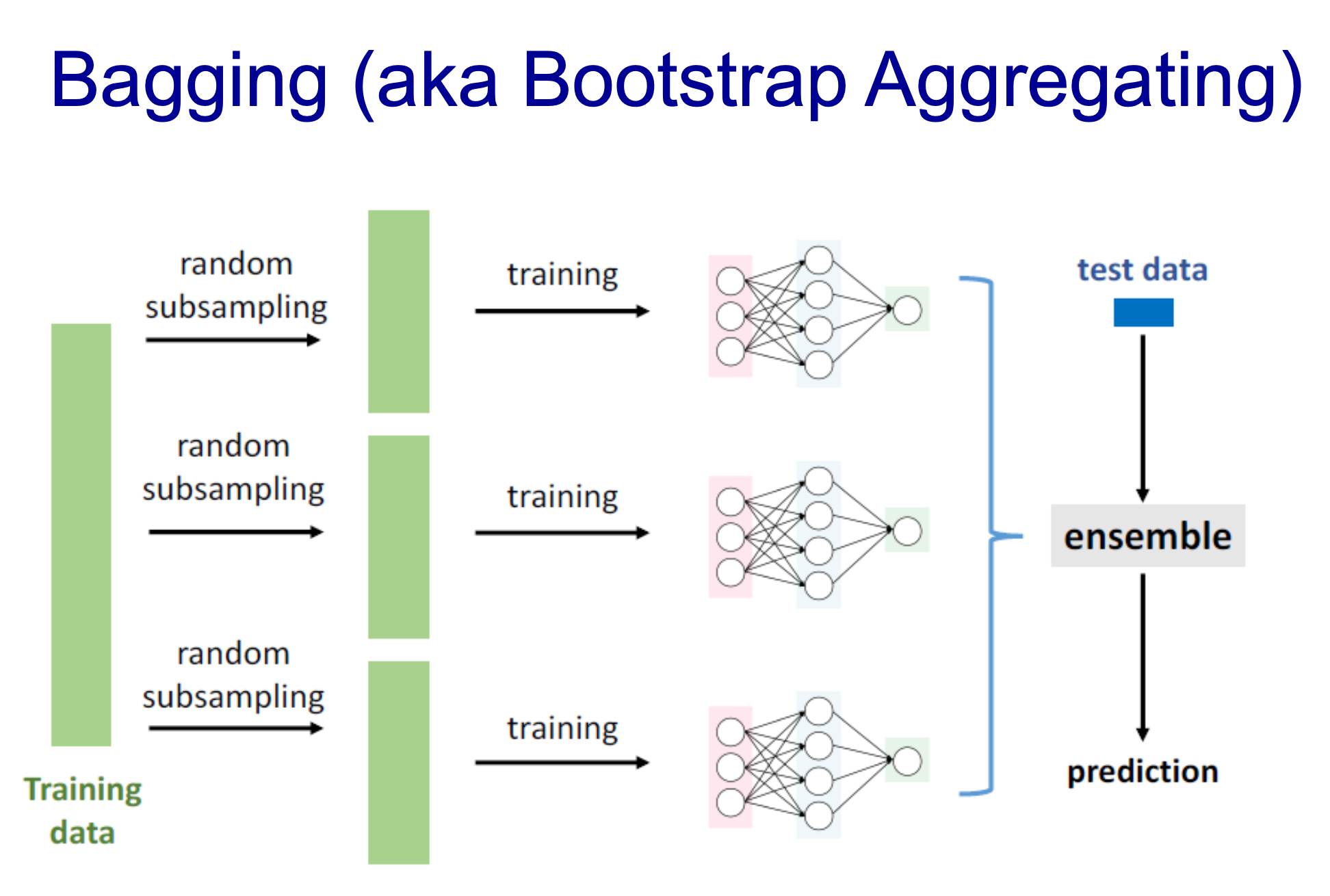
- assemble하는 게 더 좋은 결과를 만들어낼 수 있음
- data sample, parameter 초기값 변경, optimizer 변경 등 많은 방법을 적용할 수 있음
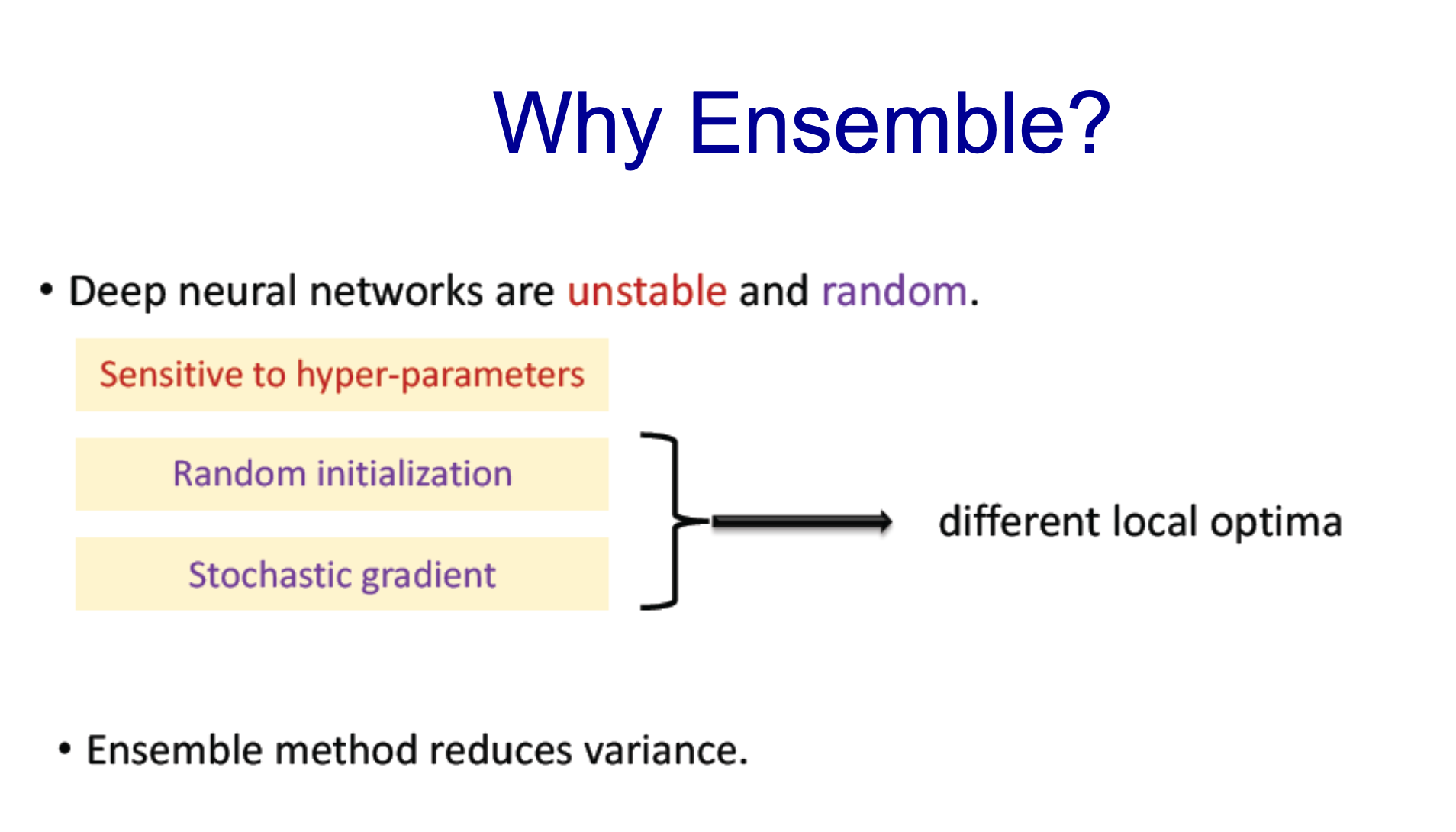
- network deep이 깊어질 수록 네트워크는 불안정
- Ensemble을 통해 variance를 reduce하여 이를 완화하고자 하는 것
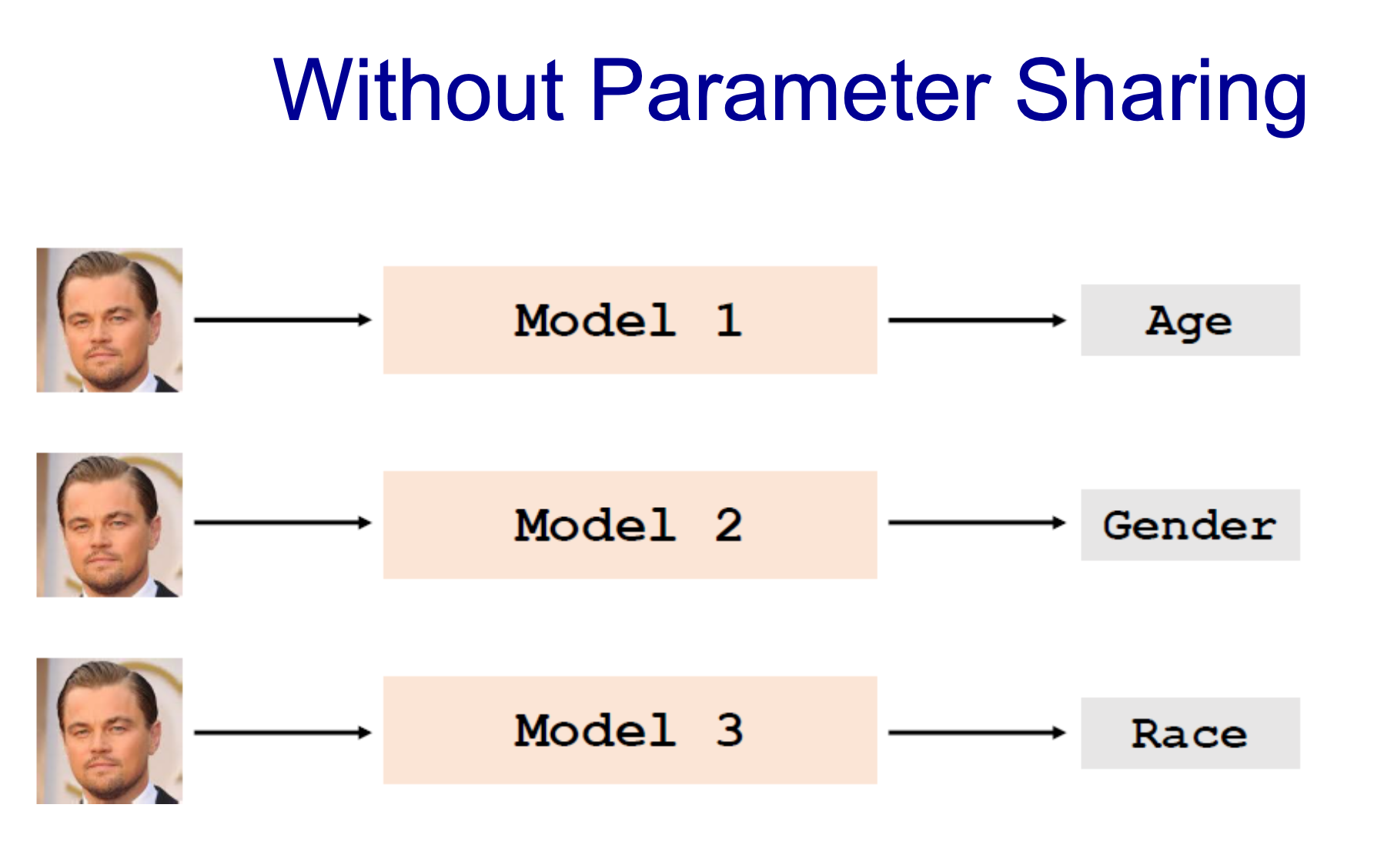
- 사진을 통해 추출할 수 있는 정보가 다름
- 이미지는 같은데 모델을 다르게 만들어야하나?
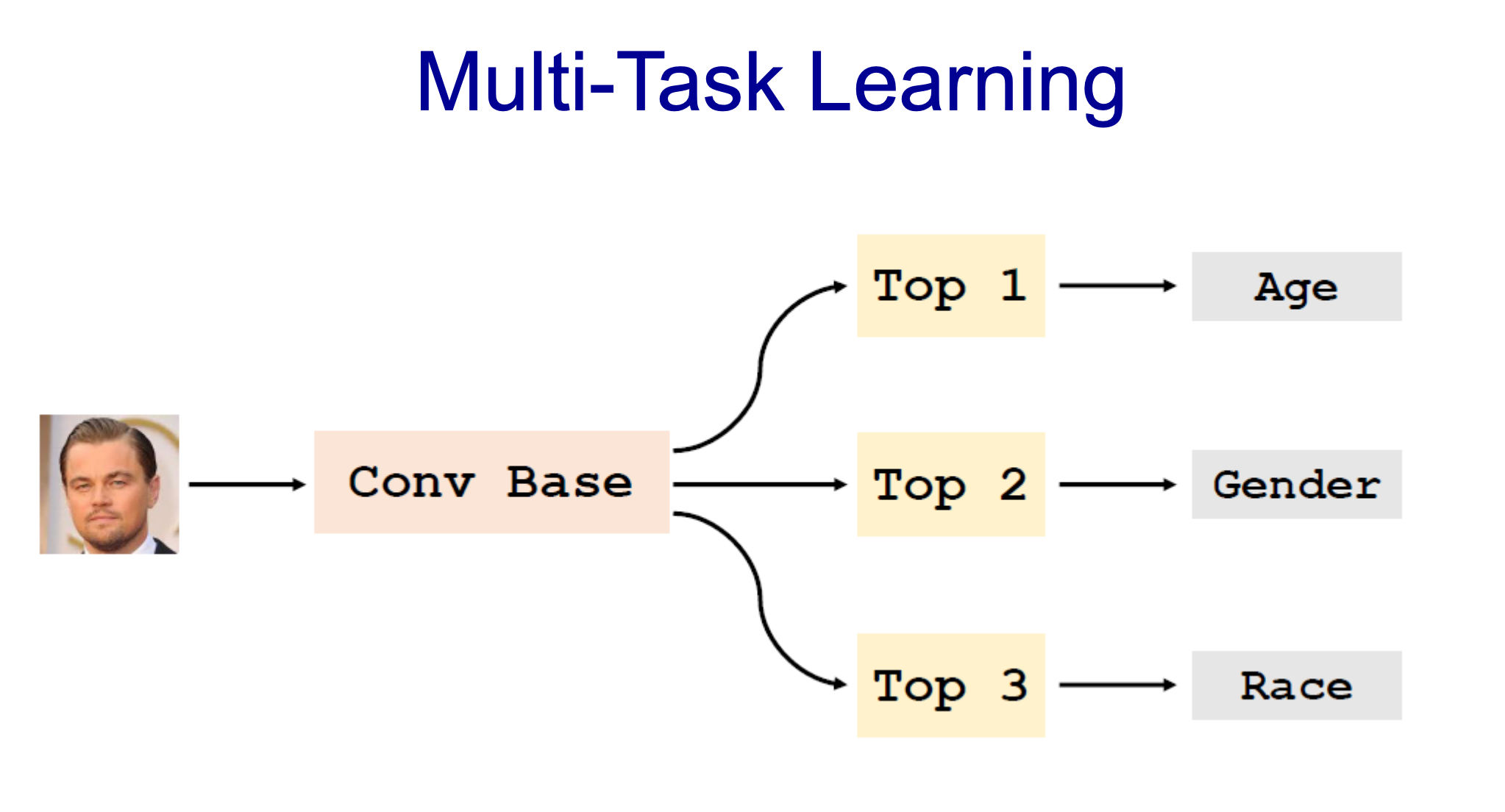
- Conv Base를 통해 하나로 묶고 마지막 layer만 다르게 하여 결과 추출나이 (0 ~ 100)

- sex (Binary)
- Race(인종 : 0-5)
- 서로 range가 다름
- 똑같이 loss를 합치는 것이 아님
- hyper-parameter를 적용하여 비슷한 loss값으로 맞춤
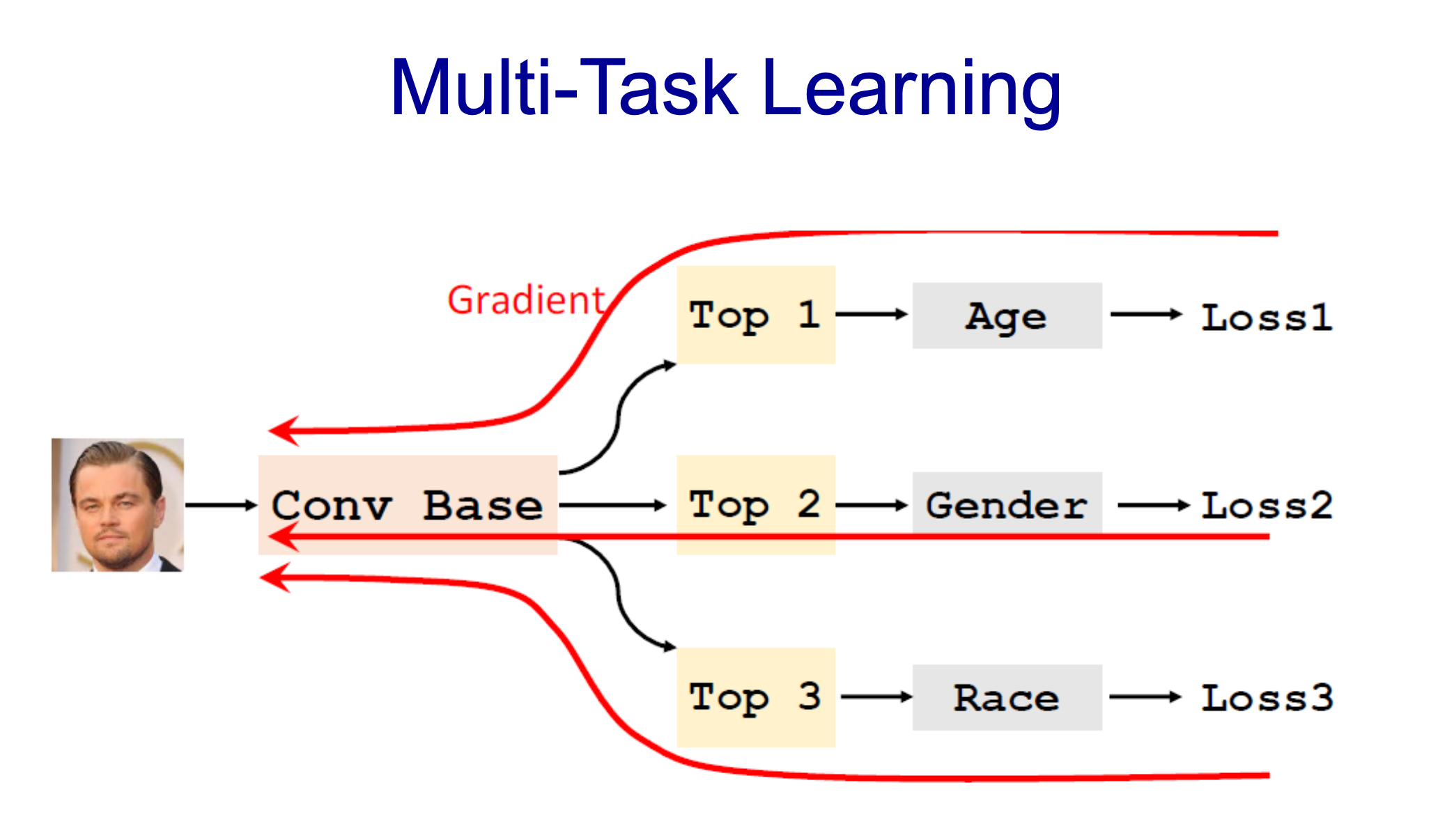
- Back propagation했을 떄 균등하게 될 수 있도록

-> 오늘 배운 5가지

- 추가적인 기법 매우 많음
728x90
반응형
'2023 > 2023-1' 카테고리의 다른 글
| Spring Cloud Config 적용 및 정리 (0) | 2023.05.11 |
|---|---|
| [캡스톤 디자인] 5월 10일 (0) | 2023.05.10 |
| [5월 4일(목)] 인공지능 입문(이론) - CNN & ComputerVision (0) | 2023.05.04 |
| [5월 4일(목) : 과제] 인공지능 입문(이론) - Neural Network (2) (0) | 2023.05.04 |
| [4월 27일(목)] 인공지능 입문(이론) - Neural Network (0) | 2023.04.27 |