MySQL에서도 쿼리를 최적으로 실행하기 위해 각 테이블의 데이터가 어떤 분포로 저장돼 있는지 통계 정보를 참조하며, 그러한 기본 데이터를 비교해 최적의 실행 계획을 수립하는 작업이 필요하다.
MySQL 서버를 포함한 대부분의 DBMS에서는 옵티마이저가 이러한 기능을 담당한다.
▶ 쿼리 실행 절차
MySQL 서버에서 쿼리가 실행되는 과정은 크게 세 단계로 나눌 수 있다.
- 사용자로부터 요청된 SQL 문장을 잘게 쪼개서 MySQL 서버가 이해할 수 있는 수준으로 분리(파스 트리)한다.
- SQL의 파싱 정보(파스 트리)를 확인하면서 어떤 테이블로부터 읽고 어떤 인덱스를 이용해 테이블을 읽을지 선택한다.
- 두 번째 단계에서 결정된 테이블의 읽기 순서나 선택된 인덱스를 이용해 스토리지 엔진으로부터 데이터를 가져온다.
- 첫 번째 단계를 "SQL 파싱(Parsing)"이라고 하며, MySQL 서버의 "SQL 파서"라는 모듈로 처리한다. SQL 문장이 문법적으로 잘못됐다면 이 단계에서 걸러진다. 또한 이 단계에서 "SQL 파스 트리"가 만들어진다.
- MySQL 서버는 SQL 문장 그 자체가 아니라 SQL 파스 트리를 이용해 쿼리를 실행한다. 두 번째 단계는 첫 번째 단계에서 만들어진 SQL 파스 트리를 참조하면서 다음과 같은 내용을 처리한다.
[1. SQL 파스 트리]
- 불필요한 조건 제거 및 복잡한 연산의 단순화
- 여러 테이블의 조인이 있는 경우 어떤 순서로 테이블을 읽을지 결정
- 각 테이블에 사용된 조건과 인덱스 통계 정보를 이용해 사용할 인덱스를 결정
- 가져온 레코드들을 임시 테이블에 넣고 다시 한번 가공해야 하는지 결정
[2. 최적화 및 실행 계획 수립]
- MySQL 서버의 "옵티마이저"에서 처리한다.
- 또한 두 번째 단계가 완려되면 쿼리의 "실행 계획"이 만들어진다.
[3. 수립된 실행 계획대로 스토리지 엔진에 레코드를 읽어오도록 요청]
- MySQL 엔진에서는 스토리지 엔진으로부터 받은 레코드를 조인하거나 정렬하는 작업을 수행한다.
→ 첫 번째 단계와 두 번째 단계는 거의 MySQL 엔진에서 처리하며, 세 번째 단계는 MySQL 엔진과 스토리지 엔진이 동시에 참여해서 처리
▶ 옵티마이저의 종류
옵티마이저는 현재 대부분의 DBMS가 선택하고 있는 비용 기반 최적화(Cost Based Optimizer, CBO) 방법과 예전 초기 버전의 오라클 DBMS에서 많이 사용했던 규칙 기반 최적화(Rule Based Optimizer, RBO)로 크게 나눌 수 있다.
- 규칙 기반 최적화 [Rule Based Optimizer : RBO)
: 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립하는 방식
- 비용 기반 최적화 [Cost Based Optimizer : CBO]
: 최소로 소요되는 처리 방식을 선택해 최종적으로 쿼리를 실행
▶ 기본 데이터 처리
기본적인 데이터 가공을 위해 MySQL 서버가 어떤 알고리즘을 사용하는지 살펴본다.
[ 풀 테이블 스캔 ]
: 인덱스를 사용하지 않고 테이블의 데이터를 처음부터 끝까지 읽어서 요청된 작업을 처리하는 작업을 의미한다.
MySQL 옵티마이저는 다음과 같은 조건이 일치할 때 주로 풀 테이블 스캔을 선택한다.
< 조건 >
- 테이블의 레코드 건수가 너무 작아서 인덱스를 통해 읽는 것보다 풀 테이블 스캔을 하는 편이 더 빠른 경우 (일반적으로 테이블이 페이지 1개로 구성된 경우)
- WHERE 절이나 ON 절에 인덱스를 이용할 수 있는 적절한 조건이 없는 경우
- 인덱스 레인지 스캔을 사용할 수 있는 쿼리라고 하더라도 옵티마이저가 판단한 조건 일치 레코드 건수가 너무 많은 경우 (인덱스의 B-Tree를 샘플링해서 조사한 통계 정보 기준)
MySQL에는 풀 테이블 스캔을 실행할 때 한꺼번에 몇 개씩 페이지를 읽어올지 설정하는 시스템 변수는 없다. 그래서 많은 사람들이 MySQL은 풀 테이블 스캔을 실행할 때 디스크로부터 페이지를 하나씩 읽어 오는 것으로 생각한다.
위 내용은 MyISAM 스퇴지 엔진에는 맞는 이야기지만 InnoDB에서는 틀린 말이다. InnoDB 스토리지 엔진은 특정 테이블의 연속된 데이터 페이지가 읽히면 백그라운드 스레드에 의해 리드 어헤드(Read ahead) 작업이 자동으로 시작된다.
※ 리드 어헤드(Read ahead) : 어떤 영역의 데이터가 앞으로 필요해지리라는 것을 예측해서 요청이 오기 전에 미리 디스크에서 읽어 InnoDB의 버퍼 풀에 가져다 두는 것을 의미한다.
즉, 풀 테이블 스캔이 실행되면 처음 몇 개의 데이터 페이지는 포그라운드 스레드(Foreground thread, 클라이언트 스레드)가 페이지 읽기를 넘겨받는 시점부터는 한 번에 4개 또는 8개씩의 페이지를 읽으면서 계속 그 수를 증가시킨다.
포그라운드 스레드는 미리 버퍼 풀에 준비된 데이터를 가져다 사용하기만 하면 되므로 쿼리가 상당히 빨리 처리되는 것이다.
[ 풀 인덱스 스캔 ]
리드 어헤드는 풀 테이블 스캔에서만 사용되는 것이 아니라 풀 인덱스 스캔에서도 동일하게 사용된다. 풀 테이블 스캔이 테이블을 처음부터 끝까지 스캔하는 것을 의미하듯이, 풀 인덱스 스캔은 인덱스를 처음부터 끝까지 스캔하는 것을 의미한다. 예를 들어, 다음과 같은 쿼리를 한번 생각해보자.
mysql> SELECT COUNT(*) FROM employees;
이 쿼리는 아무런 조건 없이 employees 테이블의 레코드 건수를 조회하고 있으므로 당연히 풀 테이블 스캔을 할 것처럼 보인다.
하지만 실제 실행 계획은 풀 테이블 스캔보다는 풀 인덱스 스캔을 하게 될 가능성이 높다. MySQL 서버는 앞의 예제와 같이 단순히 레코드의 건수만 필요로 하는 쿼리라면 용량이 작은 인덱스를 선택하는 것이 디스크 읽기 횟수를 줄일 수 있기 때문이다.
일반적으로 인덱스는 테이블의 2~3개 칼럼만으로 구성되기 때문에 테이블 자체보다는 용량이 작아서 훨씬 빠른 처리가 가능하다.
하지만 다음과 같이 레코드에만 있는 칼럼이 필요한 쿼리의 경우에는 풀 인덱스 스캔을 활용하지 못하고 풀 테이블 스캔을 한다.
mysql> SELECT * FROM employees;
▶ 기본 데이터 처리 - ORDER BY 처리 (Using filesort)
정렬을 처리하는 방법은 인덱스를 이용하는 방법과 쿼리가 실행될 때 "Filesort"라는 별도의 처리를 이용하는 방법으로 나눌 수 있다.
| 장점 | 단점 | |
| 인덱스 이용 | INSERT, UPDATE, DELETE 쿼리가 실행될 때 이미 인덱스가 정렬돼 있어서 순서대로 읽기만 하면 되므로 매우 빠르다. | INSERT, UPDATE, DELETE 작업 시 부가적인 인덱스 추가/삭제 작업이 필요하므로 느리다. 인덱스 때문에 디스크 공간이 더 많이 필요하다. 인덱스의 개수가 늘어날수록 InnoDB의 버퍼 풀을 위한 메모리가 많이 필요하다. |
| Filesort 이용 | 인덱스를 생성하지 않아도 되므로 인덱스를 이용할 때의 단점이 장점으로 바뀐다. 정렬해야 할 레코드가 많지 않으면 메모리에서 Filesort가 처리되므로 충분히 빠르다. |
정렬 작업이 쿼리 실행 시 처리되므로 레코드 대상건수가 많아질수록 쿼리의 응답 속도가 느리다. |
- 물론 레코드를 정렬하기 위해 항상 'Filesort'라는 정렬 작업을 거쳐야 하는 것은 아니다.
- 하지만 다음과 같은 이유로 모든 정렬을 인덱스를 이용하도록 튜닝하기란 거의 불가능하다.
- 정렬 기준이 너무 많아서 요건별로 모두 인덱스를 생성하는 것이 불가능한 경우
- GROUP BY의 결과 또는 DISTINCT 같은 처리의 결과를 정렬해야 하는 경우
- UNION의 결과와 같이 임시 테이블의 결과를 다시 정렬해야 하는 경우
- 랜덤하게 결과 레코드를 가져와야 하는 경우
MySQL의 정렬 특성을 이해하면 쿼리를 튜닝할 때 어떻게 하면 조금이라도 더 빠른 쿼리가 될지 쉽게 판단할 수 있다.
▶ 소트 버퍼
MySQL은 정렬을 수행하기 위해 별도의 메모리 공간을 할당받아서 사용하는데, 이 메모리 공간을 소트 버퍼(Sort Buffer)라고 한다.
소트 버퍼는 정렬이 필요한 경우에만 할당되며, 버퍼의 크기는 정렬해야 할 레코드이 크기에 따라 가변적으로 증가하지만 최대 사용 가능한 소트 버퍼의 공간은 sort_buffer_size라는 시스템 변수로 설정할 수 있다.
- 정렬해야 할 레코드가 아주 소량이어서 메모리에 할당된 소트 버퍼만으로 정렬할 수 있다면 아주 빠르게 정렬이 처리될 것이다.
- 하지만 정렬해야 할 레코드의 건수가 소트 버퍼로 할당된 공간보다 크다면 어떨까?
- 이 때 MySQL은 정렬해야 할 레코드를 여러 조각으로 나눠서 처리하는데, 이 과정에서 임시 저장을 위해 디스크를 사용한다.
메모리의 소트 버퍼에서 정렬을 수행하고, 그 결과를 임시로 디스크에 기록해 둔다. 그리고 다음 레코드를 가져와서 다시 정렬해서 반복적으로 디스크에 임시 저장한다.
이처럼 각 버퍼 크기만큼 정렬된 레코드를 다시 병합하면서 정렬을 수행해야 한다. 이 병합 작업을 멀티 머지(Multi-merge)라고 표현한다.
MySQL은 글로벌 메모리 영역과 세션(로컬) 메모리 영역으로 나눠서 생각할 수 있는데, 정렬을 위해 할다하는 소트 버퍼는 세션 메모리 영역에 해당한다.
즉, 소트 버퍼는 여러 클라이언트가 공유해서 사용할 수 있는 영역이 아니다. 커넥션이 많으면 많을수록, 정렬 작업이 많으면 많을수록 소트 버퍼로 소비되는 메모리 공간이 커짐을 의미한다.
▶ 정렬 알고리즘
레코드를 정렬할 때 레코드 전체를 소트 버퍼에 담을지 또는 정렬 기준 칼럼만 소트 버퍼에 담을지에 따라 "싱글 패스(Single-pass)"와 "투 패스(Two-pass)" 2가지 정렬 모드로 나눌 수 있다.
더 정확히는 MySQL 서버의 정렬 방식은 다음과 같이 3가지가 있다.
- <sort_key, rowid> : 정렬 키와 레코드의 로우 아이디(Row ID)만 가져와서 정렬하는 방식 : 투 패스 정렬 방식
- <sort_key, additional_fields> : 정렬 키와 레코드 전체를 가져와서 정렬하는 방식으로, 레코드의 칼럼들은 고정 사이즈로 메모리 저장 : 싱글 패스 정렬 방식
- <sort_key, packed_additional_fields> : 정렬 키와 레코드 전체를 가져와서 정렬하는 방식으로, 레코드의 칼럼들은 가변 사이즈로 메모리 저장 : 싱글 패스 정렬 방식
▶ 싱글 패스 정렬 방식
→ 소트 버퍼에 정렬 기준 칼럼을 포함해 SELECT 대상이 되는 칼럼 전부를 담아서 정렬을 수행하는 정렬 방식
→ SELECT 대상이 되는 칼럼 전부를 담기 때문에 많은 소트 버퍼 공간(메모리)이 필요
최신 버전에서는 싱글 패스 정렬 방식을 많이 사용하므로 SELECT 쿼리에서 꼭 필요한 칼럼만 조회하도록 작성한다.
▶ 투 패스 정렬 방식
→ 정렬 대상 칼럼과 프라이머리 키 값만 소트 버퍼에 담아서 정렬을 수행하고, 정렬된 순서대로 다시 프라이머리 키로 테이블을 읽어서 SELECT 할 칼럼을 가져오는 정렬 방식이다.
최신 버전 MySQL에서는 일반적으로 싱글 패스 정렬 방식을 주로 사용하지만, 다음의 경우 MySQL 서버는 싱글 패스 정렬 방식을 사용하지 못하고 투 패스 정렬 방식을 사용한다.
- 레코드의 크기가 max_length_for_sort_data 시스템 변수에 설정된 값보다 클 때
- BLOB이나 TEXT 타입의 칼럼이 SELECT 대상에 포함할 때
★ 싱글 패스 방식은 정렬 대상 레코드의 크기나 건수가 작은 경우 빠른 성능을 보이며, 투 패스 방식은 정렬 대상 레코드의 크기나 건수가 상당히 많은 경우 효율적이라고 볼 수 있다 ★
▶ 정렬 처리 방법
먼저 옵티마이저는 정렬 처리를 위해 인덱스를 이용할 수 있을지 검토할 것이다. 인덱스를 이용할 수 있다면 별도의 "Filesort" 과정 없이 인덱스를 순서대로 읽어서 결과를 반환한다. 하지만 인덱스를 사용할 수 없다면 WHERE 조건에 일치하는 레코드를 검색해 정렬 버퍼에 저장하면서 정렬을 처리할 것이다.
이 때 MySQL 옵티마이저는 정렬 대상 레코드를 최소화하기 위해 다음 2가지 방법 중 하나를 선택한다.
- 조인의 드라이빙 테이블만 정렬한 다음 조인을 수행
- 조인이 끝나고 일치하는 레코드를 모두 가져온 후 정렬을 수행
▶ 정렬 처리 방법 - ① 인덱스를 이용한 정렬 [스트리밍 처리]
- 인덱스를 이용한 정렬을 위해서는 반드시 ORDER BY에 명시된 칼럼이 제일 먼저 읽는 테이블(조인이 사용된 경우 드라이빙 테이블)에 속하고, ORDER BY의 순서대로 생성된 인덱스가 있어야 한다.
- 또한 WHERE절에 첫 번째로 읽는 테이블의 칼럼에 대한 조건이 있다면 그 조건과 ORDER BY는 같은 인덱스를 사용할 수 있어야 한다.
- 그리고 B-Tree 계열의 인덱스가 아닌 해시 인덱스나 전문 검색 인덱스 등에서는 인덱스를 이용한 정렬을 사용할 수 없다.
- 인덱스를 이용해 정렬이 처리되는 경우에는 실제 인덱스의 값이 정렬돼 있기 때문에 인덱스의 순서대로 읽기만 하면 된다. 실제로 MySQL 엔진에서 별도의 정렬을 위한 추가 작업을 수행하지는 않는다.
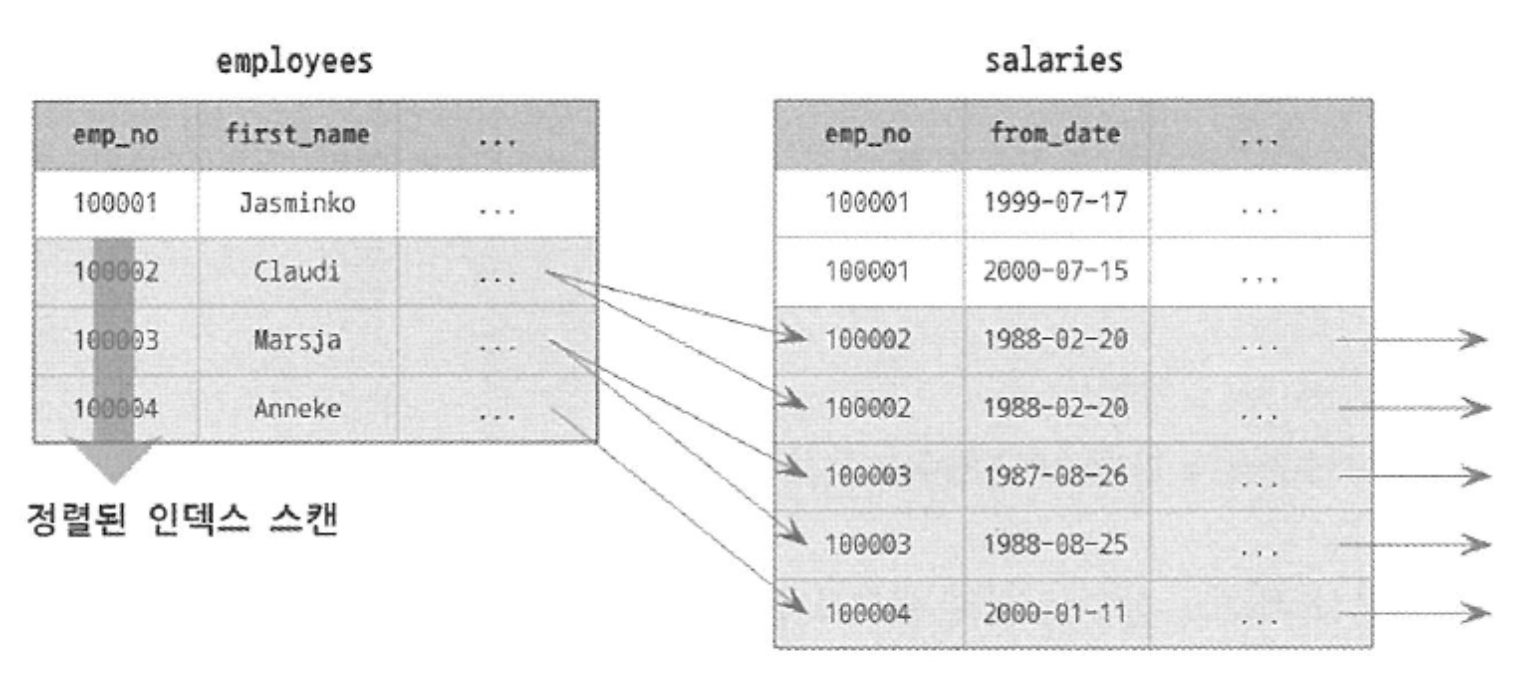
위 예제처럼 ORDER BY가 있든 없든 같은 인덱스를 레인지 스캔해서 나온 결과는 같은 순서로 출력되는 것을 확인할 수 있다.
※ ORDER BY 절을 넣지 않아도 자동 정렬되지만 ORDER BY절을 쿼리문에 작성하였을 때 정렬을 인덱스로 처리할 수 있는 경우 부가적으로 필요한 정렬 작업을 수행하지 않는다.
인덱스를 사용한 정렬이 가능한 이유는 B-Tree 인덱스가 키 값으로 정렬돼 있기 때문이다.
▶ 정렬 처리 방법 - ② 조인의 드라이빙 테이블만 정렬 [버퍼링 처리]
- 일반적으로 조인이 수행되면 결과 레코드의 건수가 몇 배로 불어나고, 레코드 하나하나의 크기도 늘어난다.
- 그래서 조인을 실행하기 전에 첫 번째 테이블의 레코드를 먼저 정렬한 다음 조인을 실행하는 것이 정렬의 차선책이 될 것이다.
- 이 방법으로 정렬이 처리되려면 조인에서 첫 번째로 읽히는 테이블(드라이빙 테이블)의 칼럼만으로 ORDER BY 절을 작성해야 한다.
mysql> SELECT * FROM employees e, salaries s WHERE s.emp_no = e.emp_no
AND e.emp_no BETWEEN 100002 AND 100010 ORDER BY e.last_name;
우선 WHERE 절이 다음 2가지 조건을 갖추고 있기 때문에 옵티마이저는 employees 테이블을 드라이빙 테이블로 선택할 것이다.
- WHERE 절의 검색 조건("emp_no BETWEEN 100001 AND 100010")은 employees 테이블의 프라이머리 키를 이용해 검색하면 작업량을 줄일 수 있다.
- 드리븐 테이블(salaries)의 조인 칼럼인 emp_no 칼럼에 인덱스가 있다.
검색은 인덱스 레인지 스캔으로 처리할 수 있지만 ORDER BY 절에 명시된 칼럼은 employees 테이블의 프라이머리 키와 전혀 연관이 없으므로 인덱스를 이용한 정렬은 불가능하다. 그런데 ORDER BY 절의 정렬 기준 칼럼이 드라이빙 테이블(employees)에 포함된 칼럼임을 알 수 있다.
옵티마이저는 드라이빙 테이블만 검색해서 정렬을 먼저 수행하고, 그 결과와 salaries 테이블을 조인한 것이다.
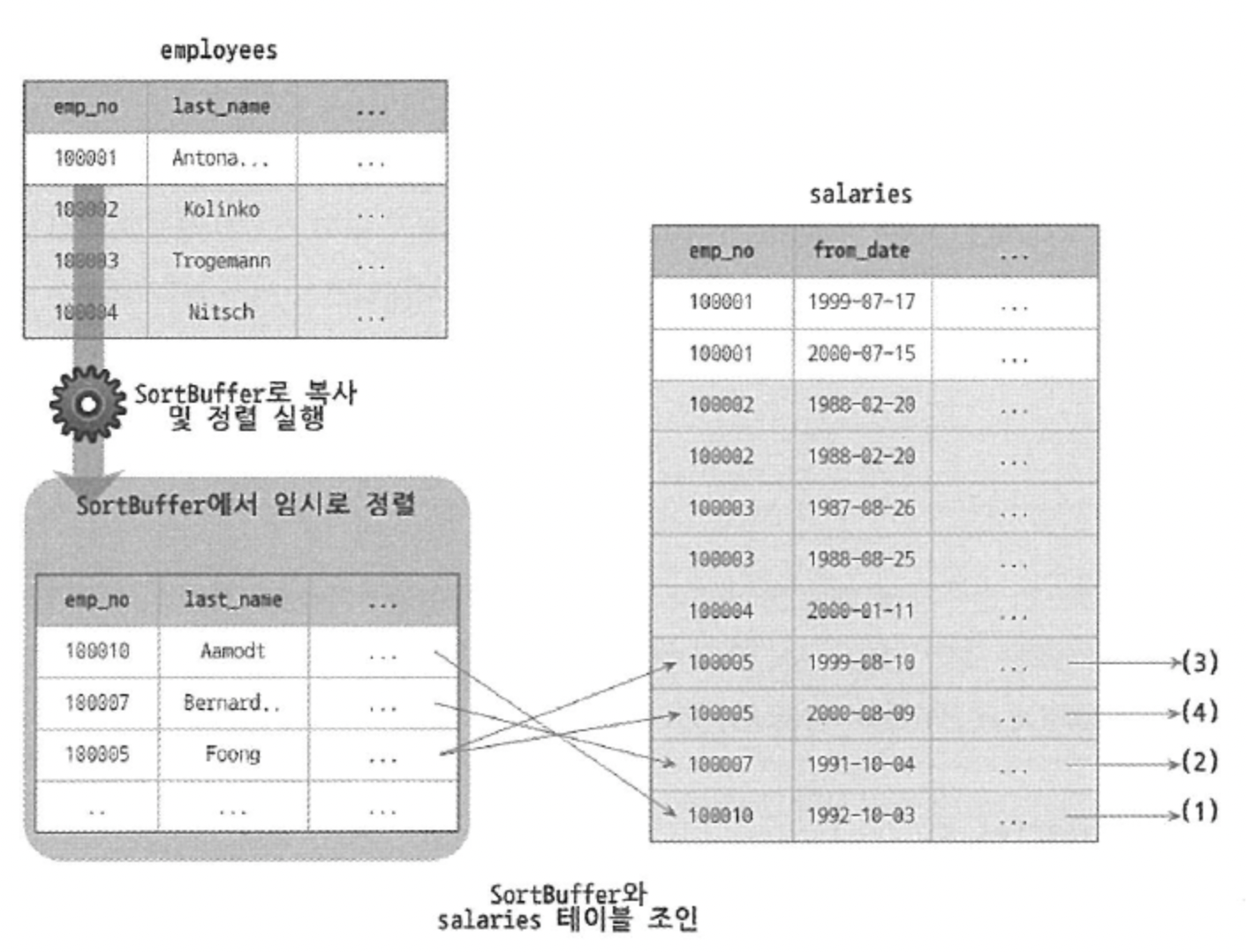
이 그림은 위에서 설명한 과정을 보여준다.
- 인덱스를 이용해 "emp_no BETWEEN 100001 AND 100010" 조건을 만족하는 9건 검색
- 검색 결과를 last_name 칼럼으로 정렬 수행(Filesort)
- 정렬된 결과를 순서대로 읽으면서 salaries 테이블과 조인을 수행
▶ 정렬 처리 방법 - ③ 임시 테이블을 이용한 정렬 [버퍼링 처리]
쿼리가 여러 테이블을 조인하지 않고, 하나의 테이블로부터 SELECT 해서 정렬하는 경우라면 임시 테이블이 필요하지 않다.
하지만 2개 이상의 테이블을 조인해서 그 결과를 정렬해야 한다면 임시 테이블이 필요할 수 있다.
♤ 위에서 살펴본 "조인의 드라이빙 테이블만 정렬"은 2개 이상의 테이블이 조인되면서 정렬이 실행되지만 임시 테이블을 사용하지 않는다. 하지만 그 외 패턴의 쿼리에서는 항상 조인의 결과를 임시 테이블에 저장하고, 그 결과를 다시 정렬하는 과정을 거친다. 이 방법은 정렬의 3가지 방법 가운데 정렬해야 할 레코드 건수가 가장 많기 때문에 가장 느린 정렬 방법이다.
mysql> SELECT * FROM employees e, salaries s WHERE s.emp_no = e.emp_no
AND e.emp_no BETWEEN 100002 AND 100010 ORDER BY s.salary;
SELECT 변수 중 첫 번째 변수인 ORDER BY 절의 정렬 기준 칼럼이 다르다. 드라이빙 테이블이 아니라 드리븐 테이블(salaries)에 있는 칼럼이다. 즉 정렬이 수행되기 전에 salaries 테이블을 읽어야 하므로 이 쿼리는 조인된 데이터를 가지고 정렬할 수 밖에 없다.
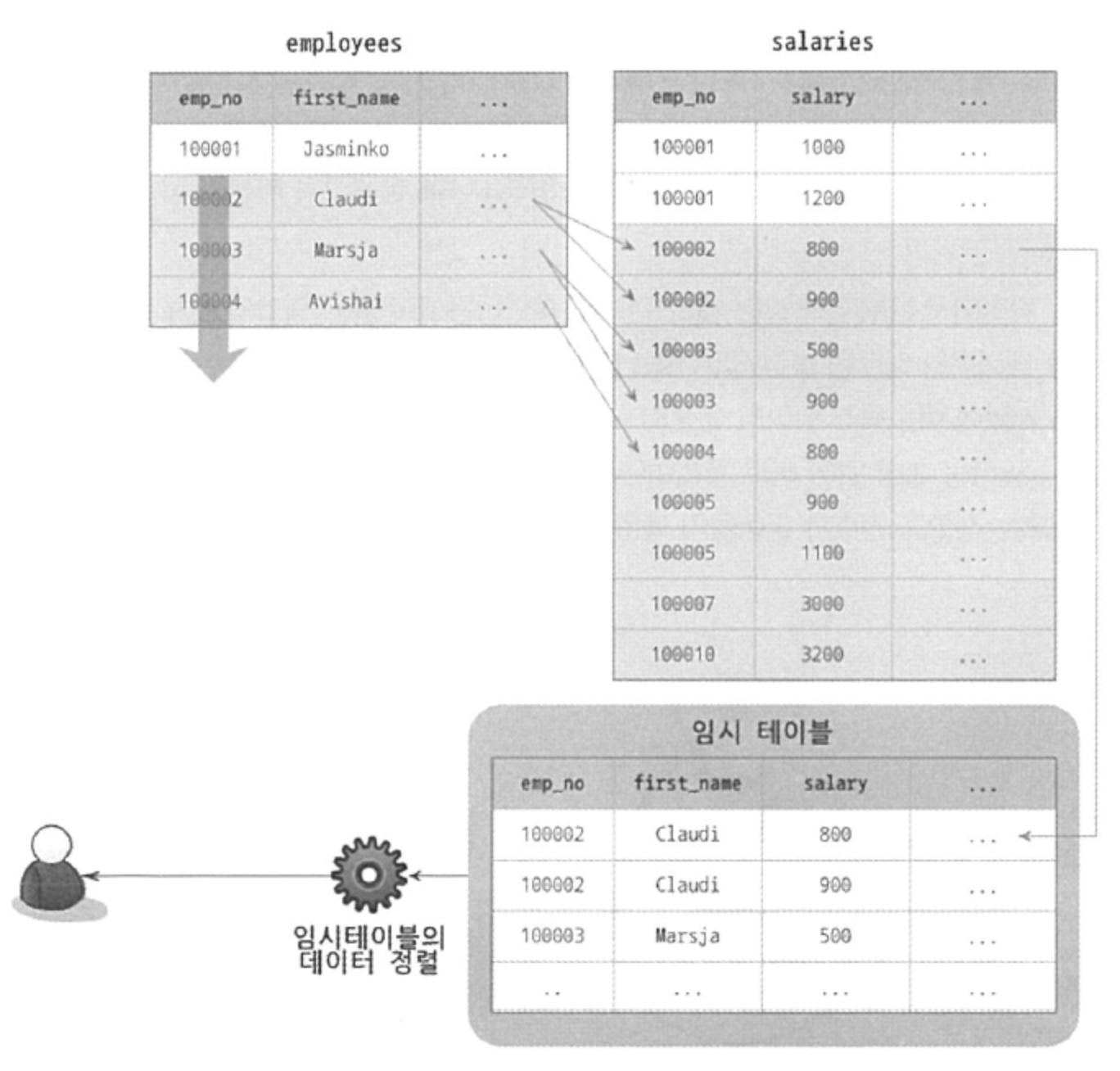
1) where 절로 데이터 읽기
2) 드라이븐 테이블과 조인하여 임시 테이블 생성
3) 임시 테이블 정렬
4) 결과 반환
▶ 정렬 처리 방법의 성능 비교
ORDER BY나 GROUP BY 같은 작업은 WHERE 조건을 만족하는 레코드를 LIMIT 건수만큼만 가져와서는 처리할 수 없다.
우선 조건을 만족하는 레코드를 모두 가져와서 정렬을 수행하거나 그루핑 작업을 실행해야만 비로소 LIMIT으로 건수를 제한할 수 있다.
WHERE 조건이 아무리 인덱스를 잘 활용하도록 튜닝해도 잘못된 ORDER BY나 GROUP BY 때문에 쿼리가 느려지는 경우가 자주 발생한다.
쿼리에서 인덱스를 사용하지 못하는 정렬이나 그루피 작업이 왜 느리게 작동할 수 밖에 없는지 쿼리가 처리되는 2가지 방법으로 구분하여 살펴본다.
▶ 정렬 처리 방법 - ① 스트리밍 방식
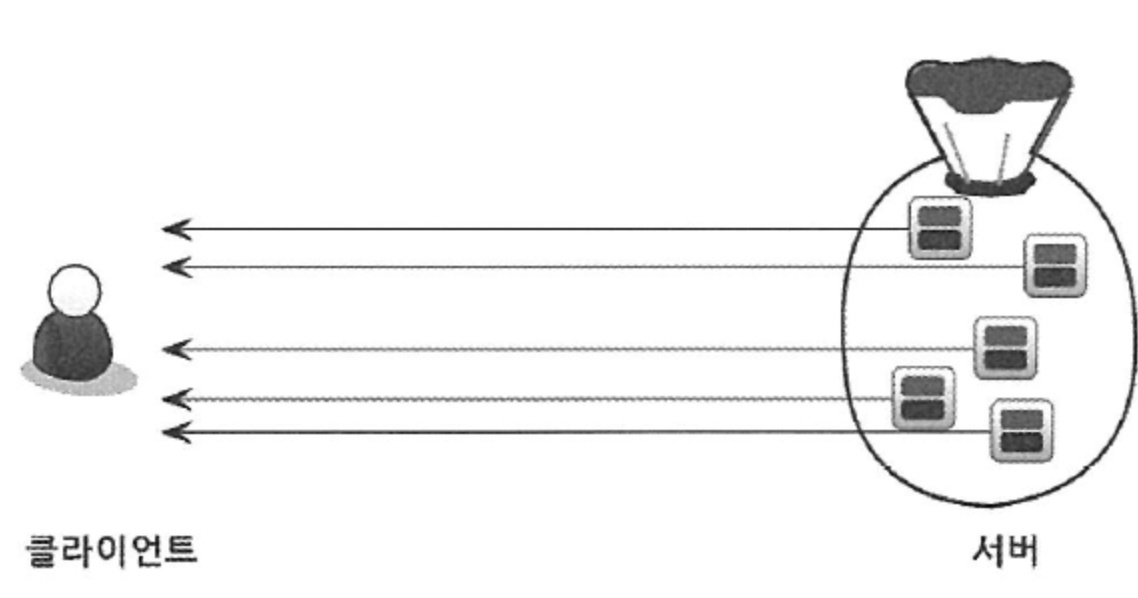
- 위 그림과 같이 조건에 일치하는 레코드가 검색될 때마다 바로바로 클라이언트로 전송해주는 방식을 의미한다.
- 클라이언트는 쿼리를 요청하고 곧바로 원했던 첫 번째 레코드를 전달받는다.
- 스트리밍 방식으로 처리되는 쿼리는 쿼리가 얼마나 많은 레코드를 조회하느냐에 상관없이 빠른 응답 시간을 보장해준다.
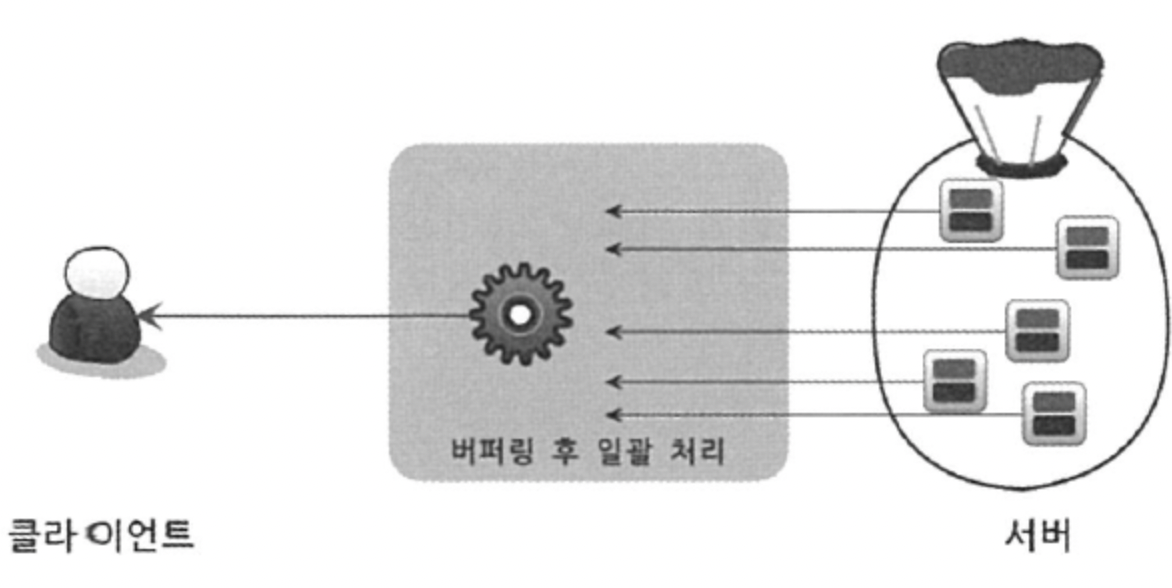
▶ 정렬 처리 방법 - ② 버퍼링 방식
- ORDER BY나 GROUP BY 같은 처리는 쿼리의 결과가 스트리밍되는 것을 부가능하게 한다. 우선 WHERE 조건절에 일치하는 모든 레코드를 가져온 후, 작업을 처리하여 차레대로 보내야 하기 때문이다.
- MySQL 서버에서는 모든 레코드를 검색하고 정렬 작업을 하는 동안 클라이언트는 아무것도 하지 않고 기다려야 하기 때문에 응답 속도가 느려진다.
- 그렇기 때문에 이 방식을 스트리밍의 반대 표현으로 버퍼링(Buffering)이라고 표현한다.
'CS > MySQL' 카테고리의 다른 글
| MySQL DISTINCT 처리, 임시테이블이 필요한 쿼리 (0) | 2023.07.14 |
|---|---|
| MySQL B-Tree 인덱스 [2/2] (0) | 2023.07.06 |
| MySQL 인덱스(index)와 B-Tree 인덱스 [1/2] (0) | 2023.07.05 |
| MySQL 데이터 압축 (페이지 압축, 테이블 압축) (0) | 2023.07.03 |
| MySQL InnoDB 스토리지 엔진 잠금과 MySQL 격리 수준 (0) | 2023.07.02 |